Bias correction with neural networks#
Authors: Jesper Dramsch, Matthew Chantry and Fenwick Cooper
This notebook was last tested and operational on 01/10/2025. Please report any issues.
About
This notebook was originally created for ECMWF’s MOOC on Machine Learning in Weather and Climate, and has been lightly updated and tested for the purposes of this collection of examples. The original notebook can be found here.
The original notebook was based on work of Matthew Chantry and Fenwick Cooper as part of work funded by IFAB. It was modified for the purposes of the MOOC by Jesper Dramsch.
Running this notebook
This notebook can be run/accessed on the following free online platforms. Please note they are not officially supported by or linked with ECMWF. See Running the notebooks for more details.
![]()

![]()
Introduction#
About surface observation processing#
Surface observation processing refers to the process of collecting and analyzing weather observations taken at the Earth’s surface by weather stations and other observing platforms. This typically includes measuring temperature, humidity, wind speed and direction, precipitation, and other meteorological variables. The observations are then used to produce weather forecasts and warnings, as well as to analyze and understand weather patterns. The process typically involves quality control checks to ensure the observations are accurate and reliable, as well as the use of automated systems to process and disseminate the observations in near real-time.
Machine learning can be applied in surface observation processing in several ways. One way is to use machine learning algorithms to help improve the accuracy of forecasts by analyzing large amounts of historical weather data. The algorithms can make more accurate predictions about future weather by learning from past weather patterns. Another way machine learning can be applied is in the quality control of the observations. Machine learning models can be trained to identify and flag any observations that may be incorrect or unreliable. This quality control can help ensure that only the most accurate and reliable weather information is used for forecasts and other purposes.
In addition, machine learning can be used to automate the process of surface observation processing, allowing the system to run more efficiently and quickly. This can help produce forecasts and warnings more quickly and with higher accuracy, providing more detailed and accurate information to the public.
Overall, the use of Machine learning in surface observation processing can help improve the accuracy and speed of weather forecasting, and provide more detailed and accurate information to the public.
In this notebook#
In this notebook, we are experimenting with deep learning techniques to solve a real-world problem that is relatively simple. The goal is to improve the temperature forecast of the ECMWF Integrated Forecast System (IFS) by using a technique called postprocessing.
Specifically, we are trying to predict the difference between the temperature observed at a weather station and the temperature forecasted by the IFS at the closest point on the grid to the station. To achieve this, we will look at several different predictors based on physical principles.
We will also get to explore several physically motivated predictors.
We will follow these steps:
Loading the data: The data consists of temperature forecast errors, time of day, and soil temperature.
Data splitting: The data is split into training and testing sets.
Data preprocessing: The data is standardized to have a mean of 0 and a standard deviation of 1.
Model building: A neural network is built using PyTorch Lightning.
Model training: The model is trained on the training data.
Model evaluation: The model is evaluated on the testing data.
Model improvement: The model can be improved by adding more predictors and complexity.
Conclusion: The results of the experiment are discussed and conclusions are drawn.
Prepare your environment#
Depending on the compute platform you are using, you may want to install the following packages in addition. These come pre-installed on some online environments like Google Colab, but not on all:
numpy
matplotlib
scikit-learn
pytorch
pytorch-lightning
We added those to the requirements.txt for your convenience. If you’re trying this exercise locally on Windows, it may be easier installing the libraries with conda. Pytorch has a guide to install locally here and Tensorflow has a guide to install locally here, which may differ from they minimal code below.
# Pytorch
!pip install torch pytorch-lightning --quiet
?25l ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.0/832.4 kB ? eta -:--:--
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 832.4/832.4 kB 23.7 MB/s eta 0:00:00
?25h?25l ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 0.0/983.2 kB ? eta -:--:--
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 983.2/983.2 kB 37.3 MB/s eta 0:00:00
?25h
We will be using some tools that are commonly used in machine learning.
Even though some of the mathematical concepts behind these tools are simple, it’s often better to use pre-existing tools that have been tested and refined by others. This will save us time and make our analysis more reliable.
import numpy as np
from sklearn import metrics
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
Before going further, we also have to download a utility function for plotting. This is contained within a plugin to the Climetlab package, which is no longer updated. In order to avoid a dependency on this package (which can cause errors in some environments), we load the function directly from the GitHub source code.
# Download the raw Python file from GitHub
!wget -O utils.py https://raw.githubusercontent.com/mchantry/climetlab-mltc-surface-observation-postprocessing/master/climetlab_mltc_surface_observation_postprocessing/utils.py
# Run it in the notebook so functions are available
%run utils.py
--2025-10-01 12:06:43-- https://raw.githubusercontent.com/mchantry/climetlab-mltc-surface-observation-postprocessing/master/climetlab_mltc_surface_observation_postprocessing/utils.py
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.109.133, 185.199.110.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 2451 (2.4K) [text/plain]
Saving to: ‘utils.py’
utils.py 100%[===================>] 2.39K --.-KB/s in 0s
2025-10-01 12:06:44 (25.9 MB/s) - ‘utils.py’ saved [2451/2451]
Loading the Data#
We will be loading a list that contains the errors of temperature forecasts made by the high-resolution forecast system of the European Centre for Medium-Range Weather Forecasts (ECMWF) for a 36-hour period. These forecasts will be compared with temperature measurements taken from about 8000 weather stations located around the world. Currently there are three variables in the dataset:
forecast_error: the difference between the forecasted value of 2m-temperature and the observed value, in °C.time_of_day: the local time of day, in decimal hours. Useful for diagnosing the diurnal cycle model bias.soil_temperature: the model soil temperature, in °C.
For each variable, the dataset contains over 5 million datapoints covering around 8000 weather stations around the world (not specified in the dataset). This may take a minute or two depending on the speed of your connection.
import numpy as np
base_url = "https://object-store.os-api.cci1.ecmwf.int/sop/"
# load in variables one at a time (.reshape() puts in correct format for later)
forecast_error = np.genfromtxt(base_url + "forecast_error.csv", delimiter=",", skip_header=1).reshape(-1, 1)
soil_temperature = np.genfromtxt(base_url + "soil_temperature.csv", delimiter=",", skip_header=1).reshape(-1, 1)
time_of_day = np.genfromtxt(base_url + "time_of_day.csv", delimiter=",", skip_header=1).reshape(-1, 1)
Let’s explicitly assign the arrays to named variables. We also reshape the time of day and soil temperature arrays to 2D arrays for compatibility with the model fitting functions.
Data Splitting#
We will be dividing the data used to make predictions and the data used to predict into two separate groups: training and testing. The training group will consist of 80% of the data and the testing group will consist of 20% of the data. This is done randomly, so that the data in each group is representative of the overall dataset.
It’s worth noting that the data has already been anonymized, so we can’t use information about the weather stations or the time the measurements were taken to make sure that the data subsets are independent. If we had more metadata, we could use the methods we learned earlier to ensure that the data subsets are not dependent on each other.
We use the function train_test_split() from the scikit-learn library.
The function takes an arbitrary number of inputs to split. Here we provide three inputs:
forecast_error: the data containing errors in forecasted temperatures,time_of_day: the data containing the local time of day when the measurements were taken,soil_temperature: the data containing the soil temperature at the location where the measurements were taken.
The function also takes in two parameters:
test_size: specifies what proportion of the data should be in the testing group. In this case, it is set to 0.2, which means that 20% of the data will be in the testing group and 80% of the data will be in the training group.random_state: used for initializing the random number generator and get the same split each time the script is run. Here it is set to42, which is an arbitrary number.
The function returns six outputs:
forecast_error_train: the data containing errors in forecasted temperatures that will be used for training,forecast_error_test: the data containing errors in forecasted temperatures that will be used for testing,time_of_day_train: the data containing the local time of day when the measurements were taken that will be used for training,time_of_day_test: the data containing the local time of day when the measurements were taken that will be used for testing,soil_temperature_train: the data containing the soil temperature at the location where the measurements were taken that will be used for training,soil_temperature_test: the data containing the soil temperature at the location where the measurements were taken that will be used for testing.
In summary, this code is splitting up the data into training and testing groups, using 80% of the data for training and 20% for testing. And it will be done in a random way and keep the same split each time the script is run by setting random_state to 42.
(
forecast_error_train,
forecast_error_test,
time_of_day_train,
time_of_day_test,
soil_temperature_train,
soil_temperature_test,
) = train_test_split(
forecast_error,
time_of_day,
soil_temperature,
test_size=0.2,
random_state=42,
)
Data Preprocessing#
The next step is to standardize the data. This is an important step that helps to prepare the data for training a neural network, especially in larger problems. To standardize the data, we will be using a method called StandardScaler() from the scikit-learn library. This method divides each data point by the mean and standard deviation of the training dataset. By doing this, it ensures that the data has a mean of 0 and a standard deviation of 1.
The code creates an instance of the StandardScaler class, and assigns it to the variable scaler. Then we use the fit() method of this scaler object, which calculates the mean and variance of the time_of_day_train data. Note that we fit this object on the training data only, to avoid cheating and accidentally creating a model that seems like it works better than it actually does.
We apply the transformation to time_of_day_train data and this creates a new variable time_of_day_train_norm which contains the standardized data.
The next line of code applies the same transformation to time_of_day_test data and creates a new variable time_of_day_test_norm which contains the standardized test data. Note that this only applies the standardization and doesn’t learn from the test data, which is valid. This is one of the big benefits of using the StandardScaler object.
In summary, this code is standardizing the time_of_day data by calculating the mean and variance of the training data and then dividing the training and testing data by those values resulting in a new set of data with mean = 0 and variance = 1.
It’s worth noting that there are other ways to prepare data for a neural network, and sometimes a different approach may be more appropriate. For example, when working with precipitation data, it may be more appropriate to use a log transform instead of standardizing the data.
scaler = StandardScaler()
scaler.fit(time_of_day_train)
print("Mean:", scaler.mean_, ", Variance:", scaler.var_)
time_of_day_train_norm = scaler.transform(time_of_day_train)
time_of_day_test_norm = scaler.transform(time_of_day_test)
Mean: [13.66310873] , Variance: [25.66713122]
Pytorch DataLoaders#
Pytorch expects a Dataloader object to provide access to the data we just created.
There are many Dataset and Dataloader objects pre-defined in the Pytorch ecosystem and we’ll use the TensorDataset to wrap our data to pass into a DataLoader.
But first we import the necessary parts from the Pytorch library:
import torch
import pytorch_lightning as pl
from torch import nn
from torch.nn import functional as F
from torch.optim import Adam
from torch.utils.data import TensorDataset, DataLoader
The first step is to convert the NumPy arrays to PyTorch tensors. This is done using the torch.from_numpy() function, which converts a NumPy array to a PyTorch tensor. The .float() at the end of the line is used to convert the tensors to a float data type.
The next step is to create a TensorDataset from the data. This dataset is created by passing the data and labels tensors to the TensorDataset constructor.
Finally, we create a DataLoader from the dataset. A DataLoader is a PyTorch utility that allows us to iterate over the dataset in batches. It takes the dataset and some options as input, such as the batch size and whether to shuffle the data. In this case, the batch size is set to 32, and the data is set to be shuffled before each epoch.
With this, you have a DataLoader that can be used to iterate over the data in batches during the training process. The DataLoader is useful for loading large datasets that do not fit into memory all at once, as it loads only a batch at a time.
We learned that we can only use the test data for a final evaluation of the model performance after we are done tweaking the model. Therefore we need to split the training data again and define a validation dataloader as well.
All of these operations will be contained within a SOPDataModule class, which provides a structured way to manage data for deep learning training in PyTorch Lightning.
class SOPDataModule(pl.LightningDataModule):
def __init__(self, train_data, train_labels, test_data, test_labels, random_state=None):
super().__init__()
self.train_data, self.val_data, self.train_label, self.val_label = train_test_split(
train_data, train_labels, test_size=0.15, random_state=random_state
)
self.test_data = test_data
self.test_label = test_labels
self.batch_size = 128
def prepare_data(self):
self.dataset_train = TensorDataset(torch.from_numpy(self.train_data).float(), torch.from_numpy(self.train_label).float())
self.dataset_val = TensorDataset(torch.from_numpy(self.val_data).float(), torch.from_numpy(self.val_label).float())
self.dataset_test = TensorDataset(torch.from_numpy(self.test_data).float(), torch.from_numpy(self.test_label).float())
def train_dataloader(self):
return DataLoader(self.dataset_train, batch_size=self.batch_size)
def val_dataloader(self):
return DataLoader(self.dataset_val, batch_size=self.batch_size)
def test_dataloader(self):
return DataLoader(self.dataset_test, batch_size=self.batch_size)
We now create an instance of the SOPDataModule class using our training and test data.
datamodule = SOPDataModule(time_of_day_train_norm, forecast_error_train, time_of_day_test_norm, forecast_error_test)
Model Building#
In Pytorch Lightning we commonly build models as a class. Within these classes, we can define models in multiple ways.
This code defines two functions: fullyconnected_sequential() and fullyconnected_functional(). Both functions create a model with a similar structure: it starts with an input layer, followed by several dense layers, and ends with an output layer.
Sequential Model#
This code is defining a PyTorch Lightning module called FullyConnected. PyTorch Lightning is a high-level library for PyTorch that makes it easier to train and evaluate deep learning models by providing a simple and consistent interface.
The constructor takes several parameters:
input_shape: an integer representing the number of predictors.width: an integer representing how wide the layers should be.depth: an integer representing how many layers the network should have.activation: a string representing the non-linear activation to use (e.g. ‘relu’, ‘sigmoid’, etc.).learning_rate: a float representing the learning rate of the optimizer (default value is 10^-3).final_activation: a string representing the activation function for the final layer(default value is ‘linear’).
We create a number of consecutive linear layers with the activation and width as input and output size respectively.
nn.Sequential is used as the model, which is a container that sequentially applies a number of modules. Then it adds the final activation and a linear layer as the output layer with the width and 1 as input and output size respectively.
The training_step() function is used to define the training loop. It takes a batch of data and the batch index, then it passes the data through the model, calculates the loss using the mean squared error loss function F.mse_loss, and logs the loss to the training log.
The configure_optimizers function is used to define the optimizer used to train the model. In this case, it is using the Adam optimizer with the learning rate that is passed to the class constructor.
This code provides a basic example of how to create a PyTorch Lightning module, define the model architecture and the training loop, and how to configure the optimizer.
class FullyConnectedSequential(pl.LightningModule):
def __init__(self, input_shape, width, depth, activation=None, learning_rate=10**(-3), final_activation=None):
super().__init__()
self.input_shape = input_shape
self.width = width
self.depth = depth
self.learning_rate = learning_rate
self.activation = activation() if activation is not None else nn.ReLU()
self.final_activation = final_activation() if final_activation is not None else nn.Identity()
self.hidden = []
for _ in range(depth):
self.hidden.append(self.activation)
self.hidden.append(nn.Linear(width, width))
self.model = nn.Sequential(nn.Linear(input_shape, width), *self.hidden, self.final_activation, nn.Linear(width, 1))
def forward(self, x):
return self.model(x)
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.mse_loss(y_hat, y)
self.log("train_loss", loss)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.mse_loss(y_hat, y)
self.log("validation_loss", loss)
return loss
def test_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.mse_loss(y_hat, y)
self.log("test_loss", loss)
return loss
def configure_optimizers(self):
opt = Adam(self.parameters(), lr=self.learning_rate)
return opt
Functional Model#
This code is defining a PyTorch Lightning module called FullyConnectedFunctional. This module is similar to the FullyConnected module that you previously explained, but it uses a functional approach to define the model architecture.
The constructor takes several parameters:
input_shape: an integer representing the number of predictors.width: an integer representing how wide the layers should be.depth: an integer representing how many layers the network should have.activation: a string representing the non-linear activation to use (e.g. ‘relu’, ‘sigmoid’, etc.).learning_rate: a float representing the learning rate of the optimizer (default value is 10^-3).final_activation: a string representing the activation function for the final layer(default value is ‘linear’).
The input, hidden and output layers are defined as functions, each function takes in a tensor and applies the linear layer and activation functions to it and return the output tensor.
The forward function is used to define the forward pass of the model. It receives an input tensor and applies the input layer to it. Then it iteratively applies the hidden layer a number of times equal to the depth of the model. Finally, it applies the output layer and return the output tensor.
The training_step function is used to define the training loop. It takes a batch of data and the batch index, then it passes the data through the model, calculates the loss using the mean squared error loss function (F.mse_loss), and logs the loss to the training log.
The configure_optimizers function is used to define the optimizer used to train the model. In this case, it is using the Adam optimizer with the learning rate that is passed to the class constructor.
This code provides a basic example of how to create a PyTorch Lightning module using a functional approach, define the model architecture and the training loop, and how to configure the optimizer.
class FullyConnectedFunctional(pl.LightningModule):
def __init__(self, input_shape, width, depth, activation=None, learning_rate=10**(-3), final_activation=None):
super().__init__()
self.input_shape = input_shape
self.width = width
self.depth = depth
self.learning_rate = learning_rate
self.activation = activation() if activation is not None else nn.ReLU()
self.final_activation = final_activation() if final_activation is not None else nn.Identity()
self.input = nn.Linear(input_shape, width)
for i in range(self.depth):
setattr(self, f"hidden{i}", nn.Linear(width, width))
self.output = nn.Linear(width, 1)
def forward(self, x):
x = self.input(x)
for i in range(self.depth):
layer = getattr(self, f"hidden{i}")
x = layer(self.activation(x))
x = self.final_activation(x)
return self.output(x)
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.mse_loss(y_hat, y)
self.log("train_loss", loss)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.mse_loss(y_hat, y)
self.log("validation_loss", loss)
return loss
def test_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.mse_loss(y_hat, y)
self.log("test_loss", loss)
return loss
def configure_optimizers(self):
opt = Adam(self.parameters(), lr=self.learning_rate)
return opt
Adam Optimiser#
When training a neural network, we use an optimization algorithm to adjust the parameters of the model in order to minimize the loss function. Notice that the optimiser we use is called Adam instead of the classic gradient descent algorithm described during the lessons.
Gradient descent is a simple optimization algorithm that updates the model’s parameters by taking a step in the direction of the negative gradient of the loss function. The step size is determined by a learning rate parameter, which controls how large the step should be. Gradient descent can work well for simple models, but can be slow to converge for more complex models.
Adam, on the other hand, is a more advanced optimization algorithm that is based on gradient descent. It uses an adaptive learning rate, which means that the step size is adjusted for each parameter based on the historical gradient information. This can help the optimization converge faster and more efficiently. Adam also includes additional features such as momentum and RMSprop, which can further improve the optimization process. This makes Adam more similar to the Conjugate Gradient method in classic numerical optimisation. Choosing Adam can improve the optimization process and make it converge faster and more efficiently.
Creating the Model#
To create a neural network object you can use either of the functions we defined above. Try changing the depth and see what the summary says:
model = FullyConnectedFunctional(
time_of_day_train_norm.shape[1], depth=3, width=32, activation="tanh", learning_rate=10**(-3)
)
model = FullyConnectedSequential(
time_of_day_train_norm.shape[1], depth=3, width=32, activation=nn.Tanh, learning_rate=10 ** (-3)
)
pl.utilities.model_summary.ModelSummary(model, max_depth=-1)
| Name | Type | Params | Mode
--------------------------------------------------------
0 | activation | Tanh | 0 | train
1 | final_activation | Identity | 0 | train
2 | model | Sequential | 3.3 K | train
3 | model.0 | Linear | 64 | train
4 | model.2 | Linear | 1.1 K | train
5 | model.4 | Linear | 1.1 K | train
6 | model.6 | Linear | 1.1 K | train
7 | model.8 | Linear | 33 | train
--------------------------------------------------------
3.3 K Trainable params
0 Non-trainable params
3.3 K Total params
0.013 Total estimated model params size (MB)
8 Modules in train mode
0 Modules in eval mode
Model training#
The fit function implements the training loop for a model in Pytorch lightning. The first two arguments passed to the fit function is the model. In this case, the training data is time_of_day_train_norm and the labels are forecast_error_train. These are the inputs and outputs that the model will use to learn during training as supplied by the dataloader. The epochs argument is the number of times the model will cycle through the data.
Once the training is done, the model will be optimized to make predictions on new data with the same features.
try:
trainer = pl.Trainer(max_epochs=3, accelerator='gpu', devices=1)
except:
print("Running on CPU will be significantly slower. Try activating a GPU backend.")
trainer = pl.Trainer(max_epochs=3)
trainer.fit(model, datamodule)
INFO:pytorch_lightning.utilities.rank_zero:💡 Tip: For seamless cloud uploads and versioning, try installing [litmodels](https://pypi.org/project/litmodels/) to enable LitModelCheckpoint, which syncs automatically with the Lightning model registry.
INFO:pytorch_lightning.utilities.rank_zero:GPU available: True (cuda), used: True
INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores
INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs
INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
INFO:pytorch_lightning.callbacks.model_summary:
| Name | Type | Params | Mode
--------------------------------------------------------
0 | activation | Tanh | 0 | train
1 | final_activation | Identity | 0 | train
2 | model | Sequential | 3.3 K | train
--------------------------------------------------------
3.3 K Trainable params
0 Non-trainable params
3.3 K Total params
0.013 Total estimated model params size (MB)
8 Modules in train mode
0 Modules in eval mode
INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=3` reached.
In other problems it may take far longer training to reach this point, or even be impossible if a network is not appropriate for the data provided.
Model Evaluation#
Finally we can do a numerical evaluation how well the model performs on unseen data.
Purely as a teaching device, we’ll also evaluate the model on training data. This number is relatively meaningless by itself, as the model will always perform well on training data as long as the model converged. The validation data is unseen as training, but was involved in the optimization process, which can have indirect optimization consequences, by us adjusting the architecture manually and generally making design choices based on the validation results.
But it’s good to learn why we test on actual unseen data and use the training value as the lower bound for our expectations of the final evaluation of the test data.
train_loss = trainer.test(dataloaders=datamodule.train_dataloader())
print("Train loss:", train_loss)
val_loss = trainer.test(dataloaders=datamodule.val_dataloader())
print("Validation loss:", val_loss)
/usr/local/lib/python3.12/dist-packages/pytorch_lightning/trainer/connectors/checkpoint_connector.py:149: `.test(ckpt_path=None)` was called without a model. The best model of the previous `fit` call will be used. You can pass `.test(ckpt_path='best')` to use the best model or `.test(ckpt_path='last')` to use the last model. If you pass a value, this warning will be silenced.
INFO:pytorch_lightning.utilities.rank_zero:Restoring states from the checkpoint path at /content/lightning_logs/version_0/checkpoints/epoch=2-step=83919.ckpt
INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
INFO:pytorch_lightning.utilities.rank_zero:Loaded model weights from the checkpoint at /content/lightning_logs/version_0/checkpoints/epoch=2-step=83919.ckpt
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Test metric ┃ DataLoader 0 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ test_loss │ 4.872727394104004 │ └───────────────────────────┴───────────────────────────┘
INFO:pytorch_lightning.utilities.rank_zero:Restoring states from the checkpoint path at /content/lightning_logs/version_0/checkpoints/epoch=2-step=83919.ckpt
INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
INFO:pytorch_lightning.utilities.rank_zero:Loaded model weights from the checkpoint at /content/lightning_logs/version_0/checkpoints/epoch=2-step=83919.ckpt
Train loss: [{'test_loss': 4.872727394104004}]
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Test metric ┃ DataLoader 0 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ test_loss │ 4.872806072235107 │ └───────────────────────────┴───────────────────────────┘
Validation loss: [{'test_loss': 4.872806072235107}]
Here we see the actual performance of our model compared based on true unseen data.
test_loss = trainer.test(dataloaders=datamodule.test_dataloader())
print("Test loss:", test_loss)
INFO:pytorch_lightning.utilities.rank_zero:Restoring states from the checkpoint path at /content/lightning_logs/version_0/checkpoints/epoch=2-step=83919.ckpt
INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
INFO:pytorch_lightning.utilities.rank_zero:Loaded model weights from the checkpoint at /content/lightning_logs/version_0/checkpoints/epoch=2-step=83919.ckpt
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━┓ ┃ Test metric ┃ DataLoader 0 ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━┩ │ test_loss │ 4.879134178161621 │ └───────────────────────────┴───────────────────────────┘
Test loss: [{'test_loss': 4.879134178161621}]
The loss metrics here represent the average squared error in the model’s predictions of temperature forecast errors. Lower values indicate better performance and generalization ability. The magnitude and comparison with other values are crucial for a meaningful interpretation.
Visualization for Evaluation#
We can create some fake data to cover the entire day and get predictions to visualize the entire space of the data.
This is not always possible, but that’s what we have this tutorial data for to gain an intuitive understanding of the methods we apply. This creates an array of time of day values spanning from 0 to 24, with a step of 0.001. This is a full range of time of day values that we want to make predictions on. The array is then reshaped to have a single axis, this is done with the [..., np.newaxis] slice.
Then we apply the same standardization procedure (using the fitted scaler object) on the full range of time of day values as the one used on the training and test data, to ensure that the new data has the same scale as the data the model was trained on.
Finally, the code uses the in-built model’s function to make predictions on the normalized full range of time of day values. The predict function returns an array of predicted forecast errors, one for each input time of day value. The variable forecast_error_full_range_predicted stores these prediction.
time_of_day_full_range = np.arange(0, 24, 0.001)[..., np.newaxis]
time_of_day_full_range_norm = scaler.transform(time_of_day_full_range)
forecast_error_full_range_predicted = model(torch.Tensor(time_of_day_full_range_norm)).detach().numpy()
Then we create an image of time of day values against forecast error values. The image is created by using a function called imgBufferFromVectors which takes a set of x and y values and creates an image.
The function takes these arguments:
time_of_day_test: the x values, representing the time of dayforecast_error_test: the y values, representing the forecast errornx: the number of pixels in the x-axis of the imageny: the number of pixels in the y-axis of the imageextent: the range of values to be plotted in the image, if empty it will use the min and max of the x and y values.calc_average: a boolean flag indicating whether to calculate the average of the input values or not.
The function then returns the image as a buffer, the extent of the axis and the count of values in the image.
tod_buffer, ax_extent, count = imgBufferFromVectors(
time_of_day_test, forecast_error_test, nx=256, ny=256, extent=[], calc_average=False
)
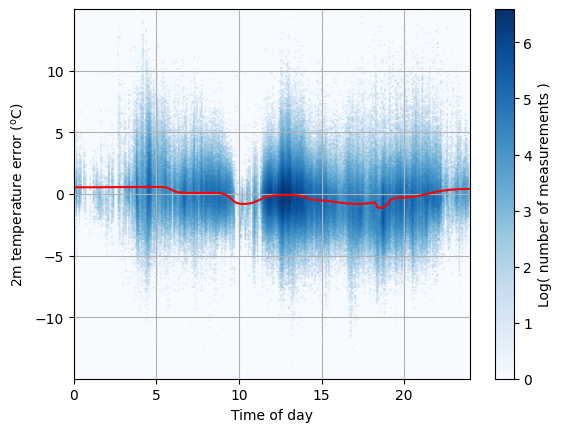
Let’s plot the number of measurements at each time of day against the forecast error.
The red line shows the best fit.
plt.imshow(np.log((count == 0.0) + count), cmap="Blues", origin="lower", extent=ax_extent, aspect="auto")
plt.xlim([0, 24])
plt.grid()
plt.xlabel("Time of day")
plt.ylabel(r"2m temperature error ($^\mathrm{o}$C)")
cb = plt.colorbar()
cb.set_label("Log( number of measurements )")
# Line of best fit
plt.plot(time_of_day_full_range, forecast_error_full_range_predicted, "red")
plt.show()
Improving the Model#
Now we can start to play around.
Let’s add more predictors.
We will add a second predictor, the model soil temperature. As we will see below, there is a complex structure in the pattern of forecast error in the 2D space of time of day & soil temperature.
How well can the model learn this?
Visualize the Soil Temperature Data#
This code is plotting a 2D histogram of the relationship between forecast error, soil temperature and time of day.
Notice how blue shows that the observation is warmer than the forecast and red shows that forecast is warmer than the observation.
# Make image of the error with the new predictor
buffer, ax_extent, count = imgBufferFromVectors(
soil_temperature_test, time_of_day_test, forecast_error_test, 128, 256, extent=[], calc_average=True
)
# Plot the image of the error
plt.imshow(buffer, vmin=-5, vmax=5, cmap="seismic", origin="lower", extent=ax_extent, aspect="auto")
plt.grid()
plt.xlabel("Soil temperature ($^o$C)")
plt.ylabel("Local time of day (hours)")
cb = plt.colorbar()
cb.set_label("Forecast - Observation ($^o$C)")
plt.show()
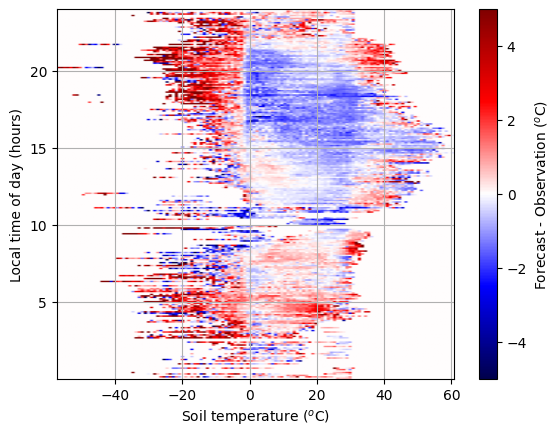
In the image above we see clear structure, where the in evening the forecast is too warm if the soil is frozen and too cold if the soil is not.
Can we learn a good representation of this error pattern?
Training a new model#
We’ll train a neural network model using two predictors, time of day and soil temperature.
The data for the two predictors is first concatenated and then standardized using StandardScaler again. Then we construct a functional model with depth and width of 3 and 32 respectively, using tanh activation function to mix things up and train.
# Create the input features
X_train = np.concatenate([time_of_day_train, soil_temperature_train], axis=-1)
X_test = np.concatenate([time_of_day_test, soil_temperature_test], axis=-1)
# Standardise the data
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
# Construct the Data Module
datamodule = SOPDataModule(X_train, forecast_error_train, X_test, forecast_error_test)
# Construct a model, this time with 2 predictors
model_with_soil = FullyConnectedFunctional(
X_train.shape[-1], depth=3, width=32, activation=nn.Tanh, learning_rate=10 ** (-3)
)
# Alternative activation functions are tanh, sigmoid, softmax, relu, softplus...
try:
trainer = pl.Trainer(max_epochs=3, accelerator='gpu', devices=1)
except:
print("Training on CPU may be significantly slower. Try activating a GPU backend.")
trainer = pl.Trainer(max_epochs=3)
trainer.fit(model_with_soil, datamodule)
INFO:pytorch_lightning.utilities.rank_zero:💡 Tip: For seamless cloud uploads and versioning, try installing [litmodels](https://pypi.org/project/litmodels/) to enable LitModelCheckpoint, which syncs automatically with the Lightning model registry.
INFO:pytorch_lightning.utilities.rank_zero:GPU available: True (cuda), used: True
INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores
INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs
INFO:pytorch_lightning.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
INFO:pytorch_lightning.callbacks.model_summary:
| Name | Type | Params | Mode
------------------------------------------------------
0 | activation | Tanh | 0 | train
1 | final_activation | Identity | 0 | train
2 | input | Linear | 96 | train
3 | hidden0 | Linear | 1.1 K | train
4 | hidden1 | Linear | 1.1 K | train
5 | hidden2 | Linear | 1.1 K | train
6 | output | Linear | 33 | train
------------------------------------------------------
3.3 K Trainable params
0 Non-trainable params
3.3 K Total params
0.013 Total estimated model params size (MB)
7 Modules in train mode
0 Modules in eval mode
INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=3` reached.
Evaluating the New Model#
Let’s do some evaluation on the unseen test data!
We’ll calculate the mean absolute error and the RMSE of the uncorrected forecast and the corrected forecast.
# Calculate Root Mean Square error of predictions:
zero_test = 0.0 * forecast_error_test
print("Mean Absolute Error Uncorrected:", metrics.mean_absolute_error(zero_test, forecast_error_test))
print("Root Mean Squared Error Uncorrected:", np.sqrt(metrics.mean_squared_error(zero_test, forecast_error_test)))
forecast_corrected = forecast_error_test - model_with_soil(torch.Tensor(X_test)).detach().numpy()
print("Mean Absolute Error Corrected:", metrics.mean_absolute_error(zero_test, forecast_corrected))
print("Root Mean Squared Error Corrected:", np.sqrt(metrics.mean_squared_error(zero_test, forecast_corrected)))
Mean Absolute Error Uncorrected: 1.6323756023379807
Root Mean Squared Error Uncorrected: 2.2561352539787456
Mean Absolute Error Corrected: 1.5553581104961351
Root Mean Squared Error Corrected: 2.1607192062453895
By using two predictors we can impove the forecast of 2m-temperature by ~0.1C.
Visual Evaluation#
Let’s see how the model corrects the forecast across the full 2D space.
We’ll run the trained model over a range of values for the input variables soil_temperature and time_of_day.
It first defines the range of values for these variables using nx and ny, which are the dimensions of the input buffer, and the ax_extent which is the range of values observed in the data. Then it creates the input data by stacking the meshgrid of these variable ranges using np.meshgrid, and transforms this input data using the scaler that was fit earlier on the training data. Then we predict the output using this input data and reshapes this output back to 2D plot using raw_pred.reshape(input_buffer.shape[:-1]) for us to plot!
# Run the fit model over the plot domain
# The x and y values of each point in the plot image, this covers
# the range of data observed in the data
nx = buffer.shape[0]
ny = buffer.shape[1]
x_st = np.linspace(ax_extent[0], ax_extent[1], nx) # Represents soil_temperature
y_tod = np.linspace(ax_extent[2], ax_extent[3], ny) # Represents time_of_day
# Create the input data
input_buffer = np.stack(np.meshgrid(y_tod, x_st), axis=-1)
X_plot = scaler.transform(input_buffer.reshape(-1, X_train.shape[-1]))
# Predict and reshape prediction back to 2D plot
raw_pred = model_with_soil(torch.Tensor(X_plot)).detach().numpy()
model_buffer = raw_pred.reshape(input_buffer.shape[:-1])
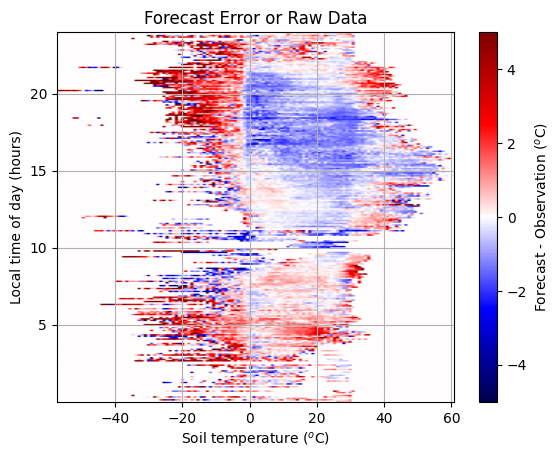
Let’s compare the images!
Notice that we’re fixing the range of the plot between -5 and 5 to make these plots intuitively comparable.
# Plot the image of the error
plt.imshow(buffer, vmin=-5, vmax=5, cmap="seismic", origin="lower", extent=ax_extent, aspect="auto")
plt.grid()
plt.title("Forecast Error or Raw Data")
plt.xlabel("Soil temperature ($^o$C)")
plt.ylabel("Local time of day (hours)")
cb = plt.colorbar()
cb.set_label("Forecast - Observation ($^o$C)")
plt.show()
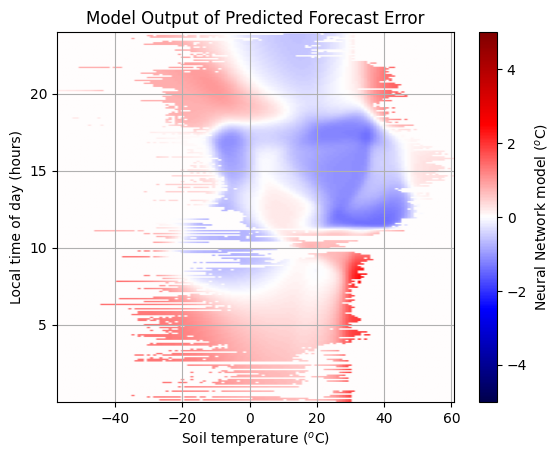
# Plot the model output where we have data
plt.imshow(
(model_buffer) * (count > 0), vmin=-5, vmax=5, cmap="seismic", origin="lower", extent=ax_extent, aspect="auto"
)
plt.grid()
plt.title("Model Output of Predicted Forecast Error")
plt.xlabel("Soil temperature ($^o$C)")
plt.ylabel("Local time of day (hours)")
cb = plt.colorbar()
cb.set_label("Neural Network model ($^o$C)")
plt.show()
# Plot the model over the whole domain
plt.imshow(model_buffer, vmin=-5, vmax=5, cmap="seismic", origin="lower", extent=ax_extent, aspect="auto")
plt.grid()
plt.title("Model Output of Extrapolating to the Full Domain")
plt.xlabel("Soil temperature ($^o$C)")
plt.ylabel("Local time of day (hours)")
cb = plt.colorbar()
cb.set_label("Neural Network model ($^o$C)")
plt.show()
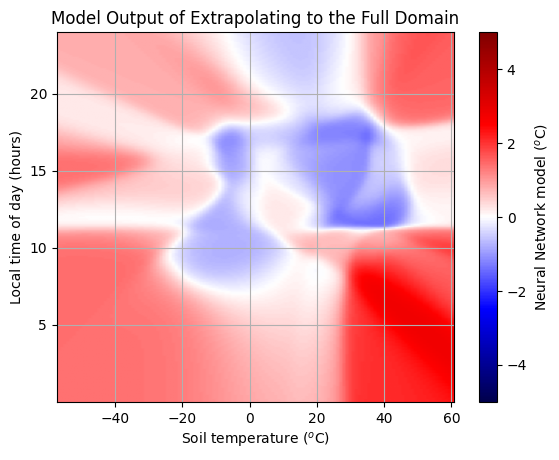
Conclusion#
As we add more predictors and complexity to our model, it becomes better and better. But, our measurements of the forecast error are not perfect. There is some noise. We don’t want our model to capture this. But an overly complex model will. We need a simpler model, or more data. Fitting a model that is too complex for the data is causes overfitting.
Here we have a large number of observations and still relatively small number of free parameters, so overfitting is unlikely. We see that during training our errors on the training & testing dataset are comparable.
Away from where data has been provided the model does not have constraints. We should not trust this part of the space without additional validation.
We also see different model corrections for hour 23 and hour 0, when these should be closely correlated, as they’re mere seconds away from each other.
Exercises#
Can you beat these predictions by changing the model architecture? Play around with activations, depth, width, learning rate of the neural network.
Is there a way of building in any prior knowledge to even this simple setup? Perhaps you can encode the fact that 0 hour follows 24? Does this help the prediction?