

CAMS-MOS#
Run the tutorial via free cloud platforms: ![]()

![]()
Learning objectives#
In this notebook we download and plot air-quality point forecasts from the CAMS Atmosphere Data Store. We use the CAMS European air quality forecasts optimised at observation sites dataset. We select one european country, from which we get the raw data and the MOS-optimised data, in CSV format, for four pollutants, \(NO_2\), \(O_3\), \(PM10\), and \(PM2.5\), from all the stations located there. For “raw” data we mean the forecasts from the gridded CAMS ensemble model interpolated over each station. A detailed description is available at the ECMWF documentation website: CAMS Regional: European Air Quality Forecast Optimised at Observation Sites data documentation. Examples of air quality data used for policy support and decision making are available at the Policy Support of the CAMS web site.
Initial setup#
Before we begin we must prepare our environment. This includes installing the Application Programming Interface (API) of the Climate Data Store (CDS), intalling any other packages not already installed, setting up our CDS API credentials and importing the various Python libraries that we will need.
# Ensure that the cdsapi package is installed
!pip install -q cdsapi
# If you are running this notebook in Colab, uncomment the line below and run this cell.
#!pip install cartopy
Add your ADS API credentials#
To set up your ADS API credentials, please login/register on the ADS, then you will see your unique API key here.
You can add this API key to your current session by replacing ######### in the code cell below with your API key.
import os
os.environ['CDSAPI_URL'] = 'https://ads.atmosphere.copernicus.eu/api'
os.environ['CDSAPI_KEY'] = '###########################################'
Import libraries#
import os
import sys
import yaml
import json
import cdsapi
import zipfile
import hashlib
import pandas as pd
import math
import datetime
from math import ceil, sqrt
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from zipfile import ZipFile
import warnings
warnings.filterwarnings('ignore')
Data access and preprocessing#
We want the raw data for four pollutants from the CAMS ensemble model and the MOS-optimised data for all the stations in the european selected country. The data is provided as CVS files. With the data an additional file with a list of the stations is also provided. All the files are zipped for download. The forecasts (lead time hours) are available for 24, 48, 72, and 96 hours starting from each of the the days that have been requested. The days of the forecasts can be in the past till the current day. So if we want the forecast from today for the next 24 hours, in the request we set the current year, month and day, e.g. 2024, 08, 28, and 0-23 for the lead time hours. The days beyond the current one will return no data. The forecasts are available for the current year and the months up to the current one.
DATADIR = '.'
Explore and download data#
Visit the download form for the CAMS global forecast data. View the parameters in the API script in the following cell and select the corresponding options.
At the end of the download form, select “Show API request”. This will reveal a block of code, which should be identical to the code cell below.
Please remember to accept the terms and conditions at the bottom of the download form.
Download data#
With the API request copied into the cell below, running this cell will retrieve and download the data you requested into your local directory.
variables = ['nitrogen_dioxide',
'ozone',
'particulate_matter_10um',
'particulate_matter_2.5um']
countries = ['netherlands']
year = '2024'
months = ['09']
days = ['13', '14']
leadtime_periods = ['0-23', '24-47']
types = ['mos_optimised', 'raw']
cams_dataset = 'cams-europe-air-quality-forecasts-optimised-at-observation-sites'
We can perform some validation tests on the settings, e.g. the last forecast starting day cannot be in the future
def validate_request_data(years, months, days, leadtime_periods):
validation_result = True
current_date = str(datetime.datetime.now())
current_year = current_date[:4]
current_month = current_date[5:7]
current_day = current_date[8:10]
days.sort()
# test forecast days
if (int(days[-1]) > int(current_day)):
print('The last forecast day must be the current one, {:s}/{}, or a previous one.'.format(current_day, current_month))
validation_result = False
# test leadtime periods
if(len(leadtime_periods) > 4):
print('The maximum lead time forecast is 4 days')
validation_result = False
return validation_result
print('The request is valid: {:b}'.format(validate_request_data(year, months, days, leadtime_periods)))
The request is valid: 1
We fill the request form with our selections
request = {
'format': 'zip',
'country': countries,
'variable': variables,
'type': types,
'leadtime_hour': leadtime_periods,
'year': year,
'month': months,
'day': days,
'include_station_metadata': 'yes',
}
Finally we send the request to the web service
import cdsapi
c = cdsapi.Client()
c.retrieve(cams_dataset, request, 'download.zip')
2024-09-14 19:58:22,532 INFO Request ID is 1cf06548-bfda-435a-aa84-50dcccfc5e24
2024-09-14 19:58:22,588 INFO status has been updated to accepted
2024-09-14 19:58:24,142 INFO status has been updated to running
2024-09-14 19:58:26,471 INFO status has been updated to successful
'download.zip'
with ZipFile(f'{DATADIR}/download.zip', 'r') as zipObj:
zipObj.extractall(path=f'{DATADIR}/download/')
Inspect data#
The stations list#
For each station in the list the following data is provided:
The European Environment Information and Observation Network (EIONET) identifier
The station’s latitude, longitude, and height
The date of start and end of the operational activity of the station
The first two characters of the identifier is the station’s country code, e.g. NL for Nederland
zip_file_list = ZipFile(f'{DATADIR}/download.zip').namelist()
zip_file_list = sorted(zip_file_list)
print('Number of zipped files: {:d} '.format(len(zip_file_list)))
Number of zipped files: 33
We write the names of the raw and MOS-optimised data files into a list
file_list = [item for item in zip_file_list if not item.startswith('station_list')]
print('Number of raw and MOS files: {:d}'.format(len(file_list)))
Number of raw and MOS files: 32
The data files#
A raw data file has the following fields
station_id
datetime
lead_time_hour
species
conc_raw_micrograms_per_m3
A MOS-optimised file has the same fields but the last one is named conc_mos_micrograms_per_m3. Each file contains the hourly concentrations of a species for one day and one lead time period from all the stations of the country specified in the request to the web service that provides data about that species. The name of the files have the following structure:
<type><lead time interval><species><day><country code>
We define a function to read the raw and MOS files and check that the station IDs are included in the stations list
def read_metadata(zip_file_list, stations=None):
"""
Reads the files included in the downloaded zip file
and returns the station metadata and
concentration data as Pandas DataFrames
"""
data = {}
for name in zip_file_list:
if name.startswith('station_list'):
# Read the station metadata file
date_fmt = '%Y-%m-%d'
file_path = DATADIR + '/download/' + name
station_data = pd.read_csv(file_path, sep=';', keep_default_na=False)
# Remove metadata for stations we're not interested in
if stations:
station_data = station_data[
station_data.id.isin(stations)]
# Set missing end dates to a date far in the future
no_end = (station_data.date_end == '')
station_data.loc[no_end, 'date_end'] = '2099-01-01'
# Parse start and end dates into datetime objects
station_data.date_start = pd.to_datetime(station_data.date_start, format=date_fmt)
station_data.date_end = pd.to_datetime(station_data.date_end, format=date_fmt)
return station_data
station_data = read_metadata(zip_file_list)
print('Total number of stations: {:d}'.format(len(station_data)))
Total number of stations: 2271
We can count the number of stations in the country that was specified in the request, in this case Nederlands.
country_code = 'NL'
country_stations = station_data[station_data['id'].str.startswith(country_code)]
num_country_stations = country_stations.shape[0]
print('Number of stations in {0:s}: {1:d}'.format(country_code, num_country_stations))
Number of stations in NL: 46
We can select one or more stations in that country
#selected_stations = None
#selected_stations = ['NL00014', 'NL00003']
selected_stations = ['NL00014']
station_data = read_metadata(zip_file_list, selected_stations)
station_data
| id | position_number | lon | lat | alt | date_start | date_end | |
|---|---|---|---|---|---|---|---|
| 1874 | NL00014 | 1 | 4.8662 | 52.35971 | 2.0 | 2024-01-17 | 2099-01-01 |
In the next step we collect the raw and MOS concentrations and then we merge the values in a single dataframe
def read_data(station_list, stations):
data = {}
for name in station_list:
# Read the station metadata file
date_fmt = '%Y-%m-%d'
# Read the data file
file_path = DATADIR + '/download/' + name
df = pd.read_csv(file_path, sep=';', parse_dates=['datetime'], infer_datetime_format=True)
# Remove data for stations we're not interested in
if stations:
df = df[df.station_id.isin(stations)]
# Get the name of the column containing concentration so we
# can group data by raw/mos type
data_col = [c for c in df.columns if c.startswith('conc_')]
assert len(data_col) == 1
data_col = data_col[0]
if data_col not in data:
data[data_col] = []
data[data_col].append(df)
return data
data = read_data(file_list, selected_stations)
data.keys()
dict_keys(['conc_mos_micrograms_per_m3', 'conc_raw_micrograms_per_m3'])
def merge_data(data_dict):
merged_data = None
for data_col in list(data_dict.keys()):
# Concatenate all times/countries/species
x = pd.concat(data[data_col])
# Merge raw and mos into combined records
if merged_data is None:
merged_data = x
else:
merged_data = merged_data.merge(x, how='outer', validate='1:1',
on=[c for c in x.columns
if c != data_col])
return merged_data
merged_data = merge_data(data)
merged_data.head()
| station_id | datetime | lead_time_hour | species | conc_mos_micrograms_per_m3 | conc_raw_micrograms_per_m3 | |
|---|---|---|---|---|---|---|
| 0 | NL00014 | 2024-09-13 00:00:00 | 0 | NO2 | 21.0 | 46.6 |
| 1 | NL00014 | 2024-09-13 00:00:00 | 0 | O3 | 15.6 | 5.8 |
| 2 | NL00014 | 2024-09-13 00:00:00 | 0 | PM10 | 6.4 | 9.7 |
| 3 | NL00014 | 2024-09-13 00:00:00 | 0 | PM2.5 | 3.4 | 7.3 |
| 4 | NL00014 | 2024-09-13 01:00:00 | 1 | NO2 | 23.2 | 41.7 |
The number of records for each station depends on the number of days from which we start the forecasts, the number of lead time periods, and the number of species that are monitored by that station
num_days = len(days)
num_leadtime_hours = len(leadtime_periods) * 24
num_species = len(merged_data.species.unique())
num_records = num_days * num_leadtime_hours * num_species
print('Total number of records: {:d}'.format(num_records))
Total number of records: 384
We can check that the number of records is what expected. In case the number is different it means that the station didn’t provide observations for all the dates and lead time periods
merged_data.shape[0] == num_records
True
Data visualization#
style = {
'type': {
'raw': {'color': 'tab:blue'},
'mos': {'color': 'tab:orange'}
},
'leadtime_day': {
0: {'linestyle': 'solid'},
1: {'linestyle': 'dashed'}
}
}
def prefs(type, leadtime, style):
"""Return pyplot.plot() keyword arguments for given type and leadtime"""
return {**style.get('type', {}).get(type, {}),
**style.get('leadtime_day', {}).get(leadtime, {})}
def plot_species(station, data, style, ax):
"""Make a plot for one species at one station"""
allspecies = data.species.unique()
assert len(allspecies) == 1
# Plotting both raw and mos-corrected or just one?
types = [t for t in ['raw', 'mos']
if f'conc_{t}_micrograms_per_m3' in data.columns]
# Plot different lines for each post-processing type and lead time day
for type in types:
lead_time_day = data.lead_time_hour // 24
for day in lead_time_day.unique():
dt = data[lead_time_day == day]
ax.plot(dt.datetime, dt[f'conc_{type}_micrograms_per_m3'],
label=f'{type} forecast D+{day}',
**prefs(type, day, style))
# Nicer date labels
ax.xaxis.set_major_formatter(mdates.DateFormatter('%H\n%a %d'))
ax.set_ylabel('$\mu$g / m$^3$')
date_range = 'from ' + ' to '.join(data.datetime.iat[i].strftime('%Y-%m-%d')
for i in [0, -1])
ax.set_title(
('{species} at {station} (lat={lat}, lon={lon}, altitude={alt}m)\n'
'{dates}').format(species=allspecies[0],
station=station.id,
lat=station.lat,
lon=station.lon,
alt=station.alt,
dates=date_range))
ax.legend()
def station_plot(station, data, style):
"""Make a series of plots for a station - one for each species"""
# Species to plot
allspecies = data.species.unique()
# Create the figure
nplotsx = ceil(sqrt(len(allspecies)))
nplotsy = ceil(len(allspecies) / nplotsx)
fig = plt.figure(figsize=(nplotsx*8, nplotsy*5))
fig.subplots_adjust(hspace=0.35)
# Plot each species
for iplot, species in enumerate(allspecies):
ax = plt.subplot(nplotsy, nplotsx, iplot + 1)
# Extract data for just this species
sdata = data[data.species == species]
plot_species(station, sdata, style, ax)
plt.show()
for station in merged_data.station_id.unique():
# Extract station metadata for just this site. If there's more than one
# entry we take the latest one that's valid within this time period
sdata = station_data.loc[
(station_data.id == station) &
(station_data.date_start <= merged_data.datetime.iloc[-1]) &
(station_data.date_end >= merged_data.datetime.iloc[0])
]
assert len(sdata), 'No metadata for site?'
sdata = sdata.iloc[-1, :]
# Extract air quality data for just this site
adata = merged_data[merged_data.station_id == station]
if len(adata) > 0:
station_plot(sdata, adata, style)
#print('Data available for ' + station)
else:
print('No data for ' + station)
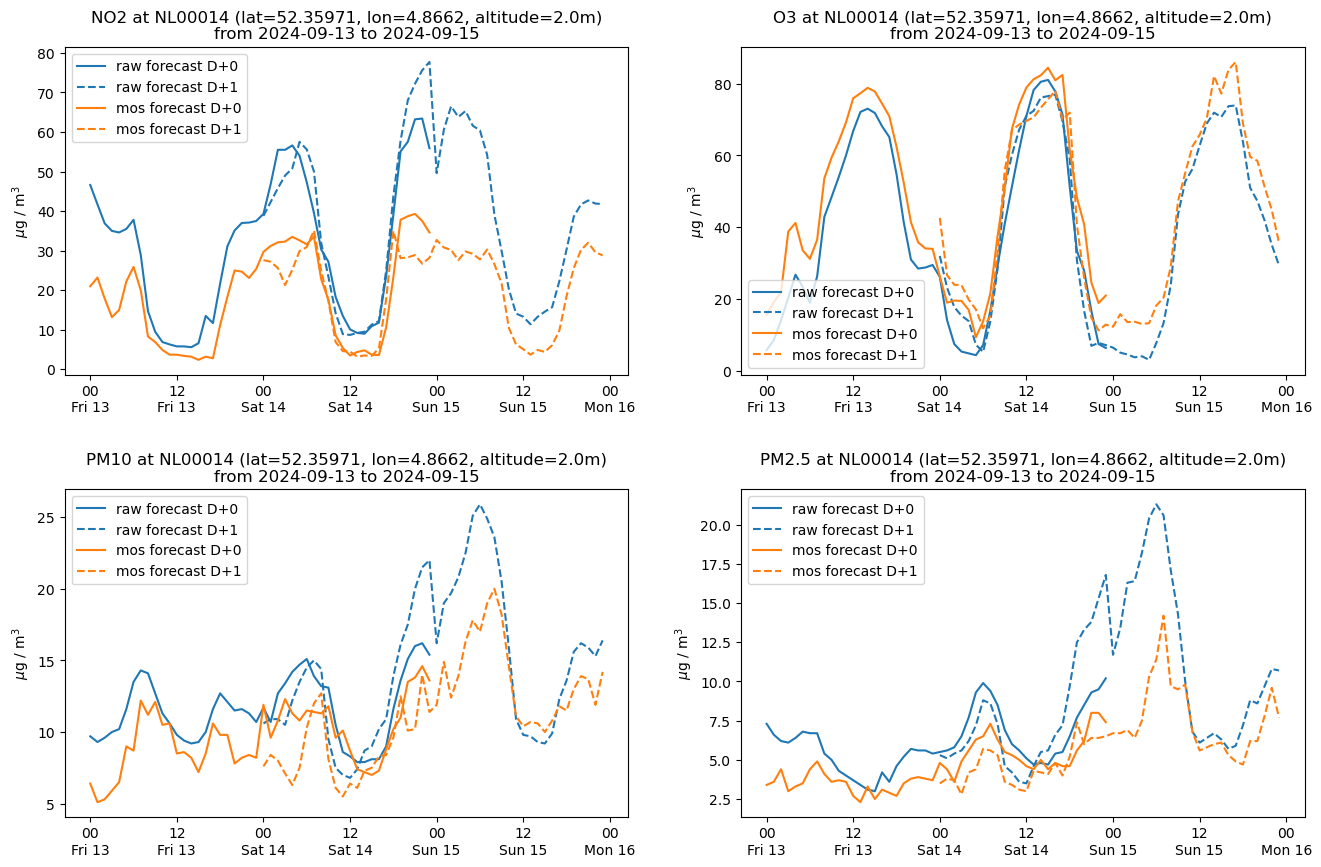
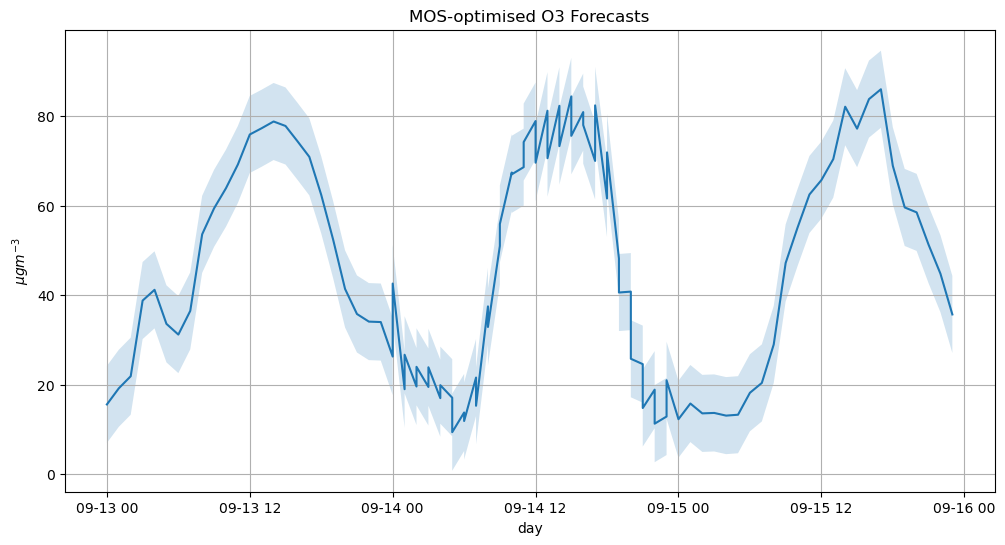
Average bias#
The raw data is also said “biased” and the MOS data is said “unbiased” or bias-corrected. We calculate the mean bias for \(NO_2\) at one station by calculating the root mean squared error RMSE
where N is the number of hourly forecasts of a species.
station_o3 = merged_data[ (merged_data['species'] == 'O3') &
(merged_data['station_id'] == 'NL00014') ] \
.drop(['station_id', 'lead_time_hour', 'species'], axis=1).sort_values(by=['datetime'])
station_o3.head(3)
| datetime | conc_mos_micrograms_per_m3 | conc_raw_micrograms_per_m3 | |
|---|---|---|---|
| 1 | 2024-09-13 00:00:00 | 15.6 | 5.8 |
| 5 | 2024-09-13 01:00:00 | 19.2 | 8.6 |
| 9 | 2024-09-13 02:00:00 | 21.9 | 14.1 |
o3_conc_mos_micrograms_per_m3 = station_o3.conc_mos_micrograms_per_m3
o3_conc_raw_micrograms_per_m3 = station_o3.conc_raw_micrograms_per_m3
o3_bias = o3_conc_mos_micrograms_per_m3 - o3_conc_raw_micrograms_per_m3
squared_o3_bias = o3_bias ** 2
rmse = math.sqrt(squared_o3_bias.mean())
print('Average O3 Raw-MOS-optimised bias: {:.2f} micrograms/m3'.format(rmse))
Average O3 Raw-MOS-optimised bias: 8.61 micrograms/m3
date_index = pd.to_datetime(station_o3['datetime'])
station_o3_time_index = station_o3.set_index(date_index).drop(['datetime'], axis=1)
station_o3_time_index.head(3)
| conc_mos_micrograms_per_m3 | conc_raw_micrograms_per_m3 | |
|---|---|---|
| datetime | ||
| 2024-09-13 00:00:00 | 15.6 | 5.8 |
| 2024-09-13 01:00:00 | 19.2 | 8.6 |
| 2024-09-13 02:00:00 | 21.9 | 14.1 |
fig = plt.figure(figsize=(12, 6))
ax = fig.add_subplot()
ax.grid(True, which='both')
ax.set_title("MOS-optimised O3 Forecasts")
ax.set_xlabel("day")
ax.set_ylabel("$\mu gm^{-3}$");
#ax.set_xticks(week_index)
#ax.set_xticklabels(week_index, rotation=70)
#ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
o3_mos = station_o3_time_index['conc_mos_micrograms_per_m3']
o3_raw = station_o3_time_index['conc_raw_micrograms_per_m3']
plt_giss_error = ax.fill_between(o3_mos.index, o3_mos - rmse, o3_mos + rmse, alpha=0.2)
plt.plot(o3_mos)
[<matplotlib.lines.Line2D at 0x21be6cbd010>]
Number of daily \(O_3\) max concentration#
We calculate the number of daily maximum concentration of PM10 above 130 \(\mu gm^{-3}\) for the MOS and and the raw ensemble forecasts.
o3_max_concentration_threshold = 130.5
station_o3_mos_max = station_o3.conc_mos_micrograms_per_m3.max()
station_o3_mos_max
np.float64(86.0)
station_o3_raw_max = station_o3.conc_raw_micrograms_per_m3.max()
station_o3_raw_max
np.float64(81.0)
station_o3_max_daily = station_o3_time_index.groupby(pd.Grouper(freq='D')).max()
station_o3_max_daily
| conc_mos_micrograms_per_m3 | conc_raw_micrograms_per_m3 | |
|---|---|---|
| datetime | ||
| 2024-09-13 | 78.8 | 73.0 |
| 2024-09-14 | 84.4 | 81.0 |
| 2024-09-15 | 86.0 | 73.9 |
#station_o3_mos_max_daily = station_o3_max_daily[station_o3_max_daily['conc_mos_micrograms_per_m3'] >
# o3_max_concentration_threshold] #.drop(['conc_raw_micrograms_per_m3'], axis=1)
#station_o3_mos_max_daily
#station_o3_raw_max_daily = station_o3_max_daily[station_o3_max_daily['conc_raw_micrograms_per_m3'] >
# o3_max_concentration_threshold].drop(['conc_mos_micrograms_per_m3'], axis=1)
#station_o3_raw_max_daily