
C3S Soil Moisture Data Access and Anomaly Analysis Notebook¶
This notebook can be run on free online platforms, such as Binder, Kaggle and Colab, or they can be accessed from GitHub. The links to run this notebook in these environments are provided here, but please note they are not supported by ECMWF.




Introduction¶
This notebook-tutorial provides a practical introduction to the Soil moisture gridded data from 1978 to present dataset available in the CDS. We give a short introduction to satellite soil moisture products, followed by a demonstrative use case where we download some data and perform a simple analyses of the observed soil moisture over selected study regions.
Please visit the CDS Soil moisture page to get an overview over the available C3S soil moisture datasets and related documentation.
Satellite sensors are capable of observing the water content in the top soil layer from space. Various satellite missions from different space agencies provide measurements of radiation from the Earth’s surface across different (microwave) frequency domains (e.g. Ku-, X-, C-, and L-band). These (raw) measurements are closely linked to the amount of water stored in the soil. There are two types of sensors that are used to measure this information: passive systems (radiometer) and active systems (radar).

For a detailed description, please see the C3S Soil Moisture Algorithm Theoretical Baseline Document, which is available along with the data on the Copernicus Climate Data Store.
Soil moisture from radiometer measurements (PASSIVE)¶
Brightness temperature is the observable radiance measured by passive sensors (expressed in ). It is a function of kinetic temperature (the actual physical temperature of the soil surface) and emissivity. Wet soils have a higher emissivity than dry soils and therefore a lower brightness temperature. Passive soil moisture retrieval uses this difference between the kinetic temperature and brightness temperature to model the amount of water available in the soil of the observed area, while taking into account factors such as the water held by vegetation.
NASA’s SMAP and ESA’s SMOS satellites are examples for L-band radiometer missions. They are suitable for retrieving soil moisture globally, even when vegetation is present in a scene.
Different models to retrieve Soil Moisture from brightness temperature measurements exist. One of the them is the Land Parameter Retrieval Model (Owe et al., 2008, Owe et al., 2001, and van der Schalie et al., 2016). This model is used to derive soil moisture for all passive sensors in C3S.
The PASSIVE product of C3S Soil Moisture contains merged observations from passive systems only. It is given in volumetric units .
Soil moisture from scatterometer measurements (ACTIVE)¶
Active systems emit radiation in the microwave domain (C-band for the data available via the CDS). As the energy pulses emitted by the radar hit the Earth’s surface, a scattering effect occurs and part of the energy is reflected back, containing information on the surface state of the observed scene. The received energy is called “backscatter”, with rough and wet surfaces producing stronger signals than smooth or dry surfaces. Backscatter comprises reflections from the soil surface layer (“surface scatter”), vegetation (“volume scatter”) and interactions of the two.
ESA’s ERS-1 and ERS-2, as well as EUMETSAT’s Metop ASCAT sensors are active systems used in C3S soil moisture. In the case of Metop ASCAT, C3S Soil Moisture uses the Surface Soil Moisture products directly provided by H SAF, based on the WARP algorithm (Wagner et al., 1999, Wagner et al., 2013).
The ACTIVE product of C3S Soil Moisture contains merged observations from active systems only. It is given in relative units .
Merged product (COMBINED)¶
Single-sensor products are limited by the life time of the satellite sensors. Climate change assessments, however, require the use of long-term data records, that span over multiple decades and provide consistent and comparable observations. The C3S Soil Moisture record therefore merges the observations from more than 15 sensors into one harmonized record. The main two steps of the product generation include scaling all sensors to a common reference, and subsequently merging them by applying a weighted average, where sensor with a lower error are assigned a higher weight.
The following figure shows all satellite sensors merged in the PASSIVE (only radiometers), ACTIVE (only scatterometers) and COMBINED (scatterometers and radiometers) C3S product (data set version v202212).

C3S Soil Moisture is based on the ESA CCI SM algorithm, which is described in Dorigo et al., 2017 and Gruber et al., 2019.
The COMBINED product is also given in volumetric units . However, the absolute values depend on the scaling reference, which is used to bring all sensors into the same dynamic range. In this case we use soil moisture simulations for the first 10 cm from the GLDAS Noah model (Rodell et al., 2004).
Prepare your environment¶
The first thing we need to do, is make sure you are ready to run the code while working through this notebook. There are some simple steps you need to do to get yourself set up.
Setup the CDSAPI and your credentials¶
The code below will ensure that the cdsapi package is installed. If you have not setup your ~/.cdsapirc file with your credentials, you can replace None with your credentials that can be found on the how to api page (you will need to log in to see your credentials).
!pip install -q cdsapi
# If you have already setup your .cdsapirc file you can leave this as None
cdsapi_key = None
cdsapi_url = None(Install and) Import libraries¶
In the next cell we import all libraries necessary to run code in this notebook. Some of them are python standard libraries, that are installed by default. If you encounter any errors during import, you can install missing packages using the conda package manager via:
!conda install -y -c conda-forge <PACKAGE>import os # os is a module that provides a way to interact with the operating system
import cdsapi # To access data programmatically from the CDS
import matplotlib.pyplot as plt # Used for creating static, animated, and interactive visualizations in Python
import cartopy # Provides tools for cartographic projections and geospatial data visualization
import cartopy.crs as ccrs # Used to handle coordinate reference systems in Cartopy maps
import xarray as xr # Facilitates working with labeled multi-dimensional arrays, particularly in the context of climate data
import pandas as pd # Provides powerful data structures like DataFrames for data manipulation and analysis
import numpy as np # Supports large, multi-dimensional arrays and matrices, along with a collection of mathematical functions
import zipfile # Enables reading and writing of ZIP archive files
import matplotlib.colors as colors # Manages color maps and normalizing data values to colors in Matplotlib
import warnings
warnings.filterwarnings("ignore") # Suppresses warnings from appearing in the outputWe also define a color map that we will use later for plotting the soil moisture data.
CM_SM = colors.LinearSegmentedColormap.from_list(
"BrownBlue",
np.array(
[
[134, 80, 16],
[164, 117, 13],
[219, 190, 24],
[250, 249, 156],
[144, 202, 240],
[4, 145, 251],
[8, 83, 211],
[13, 37, 161],
]
)
/ 255.0,
)Specify data directory¶
In the next cells we create a variable DATADIR which points to a .zip archive (either newly downloaded or the one provided with this tutorial) containing the selected data from CDS as individual images.
# Specify some filename and directories to handle the data
DATADIR = "./data_dir"
os.makedirs(DATADIR, exist_ok=True)
# Filename for the zip file downloaded from the CDS
download_zip_file = os.path.join(DATADIR, "sm_monthly_passive_v202012.zip")
# # Filename for the netCDF file which contain the merged contents of the monthly files.
merged_netcdf_file = os.path.join(DATADIR, "sm_monthly_passive_v202012.nc")Explore data¶
Different products and versions for C3S Soil Moisture are available on the Copernicus Climate Data Store. In general, there are 2 types of data records:
CDR: The long term Climate Data Record, processed every 1-2 years, contains data for more than 40 years, but not up-to-date.
ICDR: Interim Climate Data Record, updated every 10-20 days, extends the CDR, contains up-to-date (harmonised) observations to append to the CDR.
Search for the data¶
There are different options to specify a valid C3S Soil Moisture CDS data download request. You can use the CDS GUI to generate a valid request. Having selected the correct dataset, we now need to specify what parameters we are interested in. These parameters can all be selected in the “Download data” tab. In this tab a form appears in which we will select the following parameters to download:
Parameters of data to download
variable: eithervolumetric_surface_soil_moisture(must be chosen to download the PASSIVE or COMBINED data) orsurface_soil_moisture(required for ACTIVE product).type_of_sensor:active,passiveand/orcombined_passive_and_active(must match with the selected variable!).time_aggregation:month_average,10_day_average, orday_average. The original data is daily. Monthly and 10-daily averages are often required for climate analyses and therefore provided for convenience.year: a list of years to download data for (COMBINED and PASSIVE data is available from 1978 onward, ACTIVE starts in 1991).month: a list of months to download data for.day: a list of days to download data for (note that for the monthly data,daymust always be ‘01’. For the 10-daily average, validdaysare: ‘01’, ‘11’, ‘21’ (therefore the day always refers to the start of the period the data represents).type_of_record:cdrand/oricdr. It is recommended to select both, to use whichever data is available (there is no overlap between ICDR and CDR of a major version).version: Data record version, currently available:v201706,v201812,v201812,v201912,v202012(as of June 2023; new versions are added regularly). Sub-versions indicate new data that is meant to replace the previous sub-versions (necessary e.g. due to processing errors). It is therefore recommended to pass all sub-versions and use the file with the highest version for any time stamp in case of duplicate time stamps.format: Eitherziportgz. Archive format that holds the individual netcdf images.
At the end of the download form, select “Show API request”. This will reveal a block of code, which you can simply copy and paste into a cell of your Jupyter Notebook (see cell below). Having copied the API request into the cell below, running this will retrieve and download the data you requested into your local directory.
Download the data¶
# If we have not downloaded the zip file, we make the data request via the cdsapi
if not os.path.isfile(download_zip_file):
c = cdsapi.Client(url=cdsapi_url, key=cdsapi_key)
c.retrieve(
"satellite-soil-moisture",
{
"variable": "volumetric_surface_soil_moisture",
"type_of_sensor": "passive",
"time_aggregation": "month_average", # required for examples in this notebook
"year": [str(y) for y in range(1991, 2023)],
"month": [f"{m:02}" for m in range(1, 13)],
"day": "01",
"area": [72, -11, 34, 40],
"type_of_record": ["cdr", "icdr"],
"version": ["v202012"],
"format": "zip",
},
download_zip_file,
)
else:
print(f"Using previously downloaded file: {download_zip_file}")2025-10-07 17:11:59,222 INFO [2025-07-15T00:00:00] From 2025-07-14, the Active and Combined products will no longer be regularly updated due to changes in the ASCAT Soil Moisture products. The Passive product is unaffected. Regular updates of the Active and Combined products will resume upon release of v202505. Please watch the [forum](https://forum.ecmwf.int/t/temporary-change-with-cds-soil-moisture-gridded-data-updates/13801) for future announcements.
2025-10-07 17:11:59,223 INFO Request ID is f50a598e-572c-418d-9a08-376314fd0f37
2025-10-07 17:11:59,321 INFO status has been updated to accepted
2025-10-07 17:12:13,054 INFO status has been updated to running
2025-10-07 17:16:18,345 INFO status has been updated to successful
In the next cell we extract all files from the downloaded .zip archive into a new folder. We do this using standard python libraries. This step might take up to 1 minute to process during first execution!
if not os.path.isfile(merged_netcdf_file):
# Unzip the data. The dataset is split in monthly files.
with zipfile.ZipFile(download_zip_file, "r") as zip_ref:
filelist = [os.path.join(DATADIR, f) for f in zip_ref.namelist()]
zip_ref.extractall(DATADIR)
# Ensure the filelist is in the correct order:
filelist = sorted(filelist)
# Merge all unpacked files into one.
# We do this in batches of 100 files to avoid issues with dask
new_filelist = []
for i in range(int(len(filelist) / 100.0) + 1):
temp_fname = os.path.join(DATADIR, f"temp_file_{i}.nc")
new_filelist += [temp_fname]
ds = xr.open_mfdataset(filelist[i * 100 : (i * 100) + 100])
ds.to_netcdf(temp_fname)
ds = xr.open_mfdataset(new_filelist)
ds.to_netcdf(merged_netcdf_file)
# Recursively delete unpacked data
for f in filelist:
os.remove(f)
for f in new_filelist:
os.remove(f)
print(f"Preprocessing done. Netcdf stack now available at: {merged_netcdf_file}")
else:
print(f"No preprocessing required. Netcdf stack already available at: {merged_netcdf_file}")Preprocessing done. Netcdf stack now available at: ./data_dir/sm_monthly_passive_v202012.nc
Inspect data¶
We will use the library xarray to read the data. We can use the function xarrayDS. In addition, we extract the unit and valid range of the soil moisture variable from the netCDF metadata (SM_UNIT and SM_RANGE).
DS = xr.open_mfdataset(merged_netcdf_file)
SM_UNIT = DS["sm"].attrs["units"]
SM_RANGE = DS["sm"].attrs["valid_range"]Finally we plot a table that shows the contents of DS. You can see the dimensions of the data cube, coordinates assigned to each dimension, and data variables (each data point has coordinates assigned for each dimension). You can also explore the ‘Attributes’ field (i.e. metadata assigned to the data cube) by clicking on it.
DSUse case 1: Data Visualization¶
Now that we have a data cube (DS) to work with, we can start by visualizing some of the monthly soil moisture values. Our data cube DS is an xarray.Dataset, which comes with a lot of functionalities. For example we can create a simple map visualization of:
soil moisture for a certain date.
the number of observations for a certain date (note that
nobsis only available for monthly and 10-daily averaged data downloaded from CDS). Here we extract an image from the data cube using the xarray.Dataset.sel method.
In the next cell, you can select a date to plot soil moisture data. We then select the correct soil moisture (and observation count) data and create a map visualization.
Try:
Choosing a different month and year in the first line, to plot the data for a different time stamp.
DATE = "2022-05-01" # Time stamp to create plot for, you can choose a different date!
if np.datetime64(DATE) not in DS.time.values:
raise KeyError(f"{DATE} not found in data.")
# Create an empty figure with 2 subplots
fig, axs = plt.subplots(1, 2, figsize=(17, 5), subplot_kw={"projection": ccrs.PlateCarree()})
# Extract and plot the soil moisture image for chosen date using xarray.Dataset.sel and Dataset.plot:
p_sm = DS["sm"].sel(time=DATE).plot(
transform=ccrs.PlateCarree(),
ax=axs[0],
cmap=CM_SM,
cbar_kwargs={"label": f"Soil Moisture [{SM_UNIT}]"},
)
axs[0].set_title(f"{DATE} - Soil Moisture")
# Extract and plot the number of observations (nobs) image for chosen date using xarray.Dataset.sel and Dataset.plot:
if "nobs" in DS.variables:
# Note: nobs is only available for monthly and 10-daily data
p_obs = DS["nobs"].sel(time=DATE).plot(
transform=ccrs.PlateCarree(),
ax=axs[1],
vmax=31,
vmin=0,
cmap=plt.get_cmap("YlGnBu"),
cbar_kwargs={"label": "Days with valid observations"},
)
axs[1].set_title(f"{DATE} - Data coverage")
else:
p_obs = None
# Add basemape features:
for p in [p_sm, p_obs]:
if p is None:
continue
p.axes.add_feature(cartopy.feature.LAND, zorder=0, facecolor="gray")
p.axes.coastlines()
# Draw grid lines and labels for both maps:
for ax in axs:
if ax is not None:
gl = ax.gridlines(crs=ccrs.PlateCarree(), draw_labels=True, alpha=0.25)
gl.top_labels, gl.right_labels = False, False
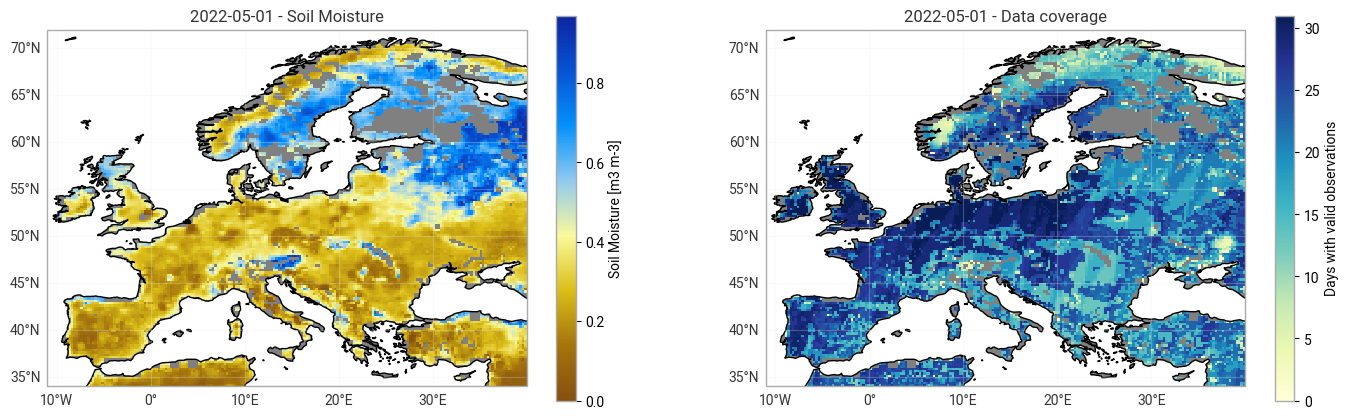
When looking at images of different dates, you can see data gaps (grey areas; especially in winter, mountainous regions and high latitude) and areas of high (blue) and low (brown) soil moisture content (left map). When changing the date to plot in the cell above, you can see that the number of observations is much larger in later periods of the record than in earlier ones due to the larger number of available satellites (right map).
Use case 2: Time Series Extraction and Analysis¶
In the following two examples we will need to set a study area and a time range. We will use a chosen ‘focus point’ assigned to the study area to extract a time series from the loaded stack at this location.
Study areas¶
First we define some potential study areas that we can use in the following applications. Below you can find a list of bounding boxes, plus one ‘focus point’ in each bounding box. You can add your own study area to the end of the list. If you do, make sure to pass the coordinates in the correct order: Each line consists of:
A name for the study area.
WGS84 coordinates of corner points of a bounding box around the study area.
WGS84 coordinates of a single point in the study area (focus area).
(<STUDY_AREA_NAME>, ([<BBOX min. Lon.>, <BBOX max. Lon.>, <BBOX min. Lat.>, <BBOX max. Lat.>], [<POINT Lon.>, <POINT Lat.>]))
BBOXES = {
# Name: ([min Lon., max Lon., min Lat., max Lat.], [Lon, Lat]))
"Balkans": ([16, 29, 36, 45], [24, 42]),
"Central Europe": ([6, 22.5, 46, 51], [15, 49.5]),
"France": ([-4.8, 8.4, 42.3, 51], [4, 47]),
"Germany": ([6, 15, 47, 55], [9, 50]),
"Iberian Peninsula": ([-10, 3.4, 36, 44.4], [-5.4, 41.3]),
"Italy": ([7, 19.0, 36.7, 47.0], [12.8, 43.4]),
"S-UK & N-France": ([-5.65, 2.5, 48, 54], [0, 51]),
}Visual representation study area¶
We will visualize the absolute monthly soil moisture values for a certain date, as we did in ‘Application 1: data visualization’. In addition, we will show the selected study area together with the data on a map. We will also show a chosen ‘focus point’ assigned to the study area, marked by the red X.
Try:
Choosing a different study area by changing the
STUDY_AREAvariable.
DATE = "2022-05-01" # Time stamp to create plot for, you can choose a different date!
STUDY_AREA = "Germany" # Specify the study area (ensure it's in BBOXES)
# Check whether the selected study area and date are available
if STUDY_AREA not in BBOXES:
raise KeyError(f"Unknown STUDY_AREA: {STUDY_AREA}. Select one of {BBOXES.keys()}")
if np.datetime64(DATE) not in DS.time.values:
raise KeyError(f"{DATE} not found in data.")
# Create a figure with a specific size and a single axis
plt.figure(figsize=(8, 5))
ax = plt.axes(projection=ccrs.PlateCarree()) # Create a single axis with a cartopy projection
# Extract and plot soil moisture image for the chosen date using xarray.Dataset.sel and Dataset.plot
p_sm = DS["sm"].sel(time=DATE).plot(
transform=ccrs.PlateCarree(),
ax=ax,
cmap=CM_SM,
cbar_kwargs={"label": f"Soil Moisture [{SM_UNIT}]"},
)
ax.set_title(f"{DATE} - Soil Moisture")
# Add basemap features
ax.add_feature(cartopy.feature.LAND, zorder=0, facecolor="gray")
ax.coastlines()
# Draw grid lines and labels for the map
gl = ax.gridlines(crs=ccrs.PlateCarree(), draw_labels=True, alpha=0.25)
gl.top_labels, gl.right_labels = False, False
bbox = BBOXES[STUDY_AREA][0]
point = BBOXES[STUDY_AREA][1]
# Add focus point of study area to the map
ax.plot(
[point[0]],
[point[1]],
color="red",
marker="X",
markersize=10,
linewidth=0,
transform=ccrs.PlateCarree(),
label = f"{STUDY_AREA} Focus Point"
)
# Add study area bounding box to the map
ax.plot(
[bbox[0], bbox[0], bbox[1], bbox[1], bbox[0]],
[bbox[2], bbox[3], bbox[3], bbox[2], bbox[2]],
color="red",
linewidth=3,
transform=ccrs.PlateCarree(),
label = f"{STUDY_AREA} Study Area"
)
# Add study area legend
ax.legend()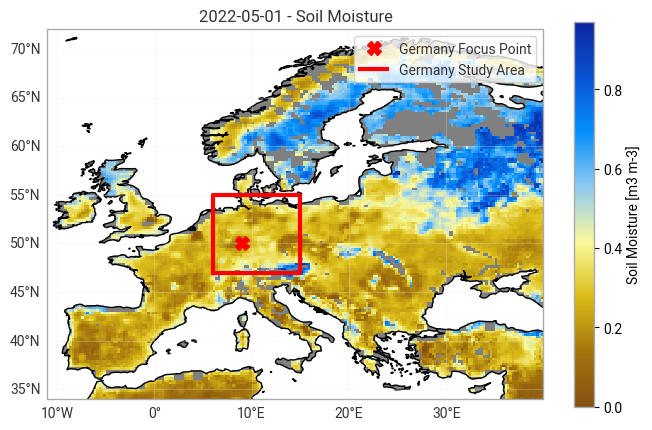
Extracting the time series data¶
We use the chosen ‘focus point’ assigned to the study area (marked by the red X in the map above) to extract a time series from the loaded stack at this location. We then compute the climatological mean (and standard deviation) for the chosen time series using the selected reference period (baseline). Finally, we subtract the climatology from the absolute soil moisture to derive a time series of anomalies. Anomalies therefore indicate the deviation of a single observation from the average (normal) conditions. A positive anomaly can be interpreted as “wetter than usual” soil moisture conditions, while a negative anomaly indicates “drier than usual” states.
Expressing anomalies¶
There are different ways to express anomalies. For example:
Absolute Anomalies: Derived using the difference between the absolute values for a month () and year () () and the climatology for the same month (). Same unit as the input data.
$\Large SMA_{k,i}^{abs} = SM_{k,i} - \overline{SM_i}$
Relative Anomalies: The anomalies are expressed relative to the climatological mean for a month (), i.e. in % above / below the expected conditions.
$\Large SMA_{k,i}^{rel}=\frac{SM_{k,i} - \overline{SM_i}}{\overline{SM_i}} \cdot 100\% $
Z-Scores: Z-scores are a way of standardizing values from different normal distributions. In the case of soil moisture, the spread of values between months can vary, e.g. due to differences in data coverage (i.e. a different distribution for values in summer than for those in winter is expected). This can affect the computed climatology and therefore the derived anomalies. By taking into account the standard deviation () of samples used to compute the climatologies, we can normalize the anomalies and exclude this effect. Z-scores therefore express the number of standard deviations a value is above / below the expected value for a month.
$\Large Z_{k,i} = \frac{SM_{k,i} - \overline{SM_i}}{\sigma_{i}}$
Note: The anomaly formulas are presented in Jupyter Notebook format and may not be viewable in a standard web browser.
Application extracting the time series data¶
First we extract a time series for the chosen ‘focus point’ of the study area (see location in the map of the previous example) and a chosen reference period.
Try:
Choosing a different study area by changing the
STUDY_AREAvariable. See Study areas defined above for your options.Choosing a different reference period by changing the
BASELINE_YEARSvariable. The first value is the start year of the reference period, the second value is the last year that is considered when computing the climatological reference.
BASELINE_YEARS = (1991, 2020) # First and last year to consider for climatology, can be changed.
STUDY_AREA = "Germany" # Try out a different study area
# Extract data at the 'focus point' of the chosen study area:
lon, lat = float(BBOXES[STUDY_AREA][1][0]), float(BBOXES[STUDY_AREA][1][1])
ts = DS["sm"].sel(lon=lon, lat=lat, method="nearest").to_pandas()
# Select the time series only for the baseline years and save it as clim_data:
time_series_data = ts.loc[f"{BASELINE_YEARS[0]}-01-01" :f"{BASELINE_YEARS[1]}-12-31"]We plot the extracted soil moisture time series, for our chosen reference years and study area:
# Create a figure with a specific size
plt.figure(figsize=(10, 2))
# Plot the soil moisture time series
time_series_data.plot(
title=f"Soil Moisture at focus point of `{STUDY_AREA}` study area (Lon: {lon}° W, Lat: {lat}° N)",
ylabel=f"SM $[{SM_UNIT}]$",
xlabel="Time [year]",
)
# Show the plot
plt.show()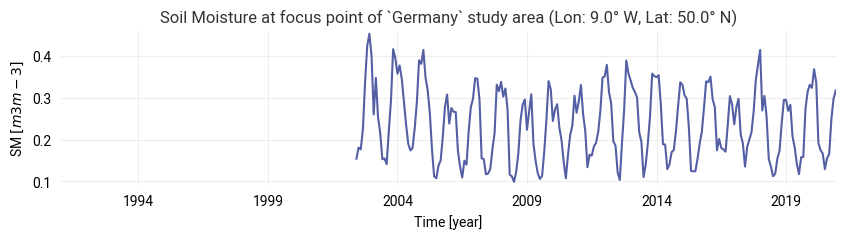
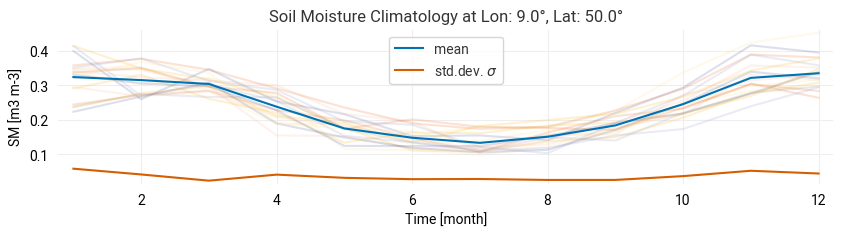
We use the time series data to compute the climatological mean and standard deviation for the chosen time series, using the selected reference period (baseline):
# Compute the required statistics:
clim_mean = pd.Series(
time_series_data.groupby(time_series_data.index.month).mean(), name="climatology"
)
clim_std = pd.Series(
time_series_data.groupby(time_series_data.index.month).std(), name="climatology_std"
)
# Save the Climatology data in the time series data frame
ts = pd.DataFrame(time_series_data, columns=["sm"])
ts["climatology"] = ts.join(on=ts.index.month, other=clim_mean)["climatology"]
ts["climatology_std"] = ts.join(on=ts.index.month, other=clim_std)["climatology_std"]Create a plot for the climatology - the mean and standard deviation for each month in the chosen baseline period:
# Create a figure with a specific size and a single axis
plt.figure(figsize=(10, 2))
ax = plt.gca()
color_mean = "#0072B2" # Blue
color_std = "#D55E00" # Orange
# Plot each year's data with transparency
for i, g in time_series_data.groupby(time_series_data.index.year):
ax.plot(range(1, 13), g.values, alpha=0.2)
# Plot the climatology mean and standard deviation
clim_mean.plot(
ax=ax,
color=color_mean,
title=f"Soil Moisture Climatology at Lon: {lon}°, Lat: {lat}°",
ylabel=f"SM [{SM_UNIT}]",
label="mean",
)
clim_std.plot(ax=ax, color=color_std, label="std.dev. $\sigma$", xlabel="Time [month]")
# Add the legend
ax.legend()
Using the above formulas (section 5.2.1 Expressing anomalies), we compute the three anomaly metrics for the extracted time series and store them in a pandas DataFrame (columns ‘abs_anomaly’, ‘rel_anomaly’ and ‘z-score’):
# Compute the anomaly metrics
ts["abs_anomaly"] = ts["sm"] - ts["climatology"]
ts["rel_anomaly"] = (ts["sm"] - ts["climatology"]) / ts["climatology"] * 100
ts["z_score"] = (ts["sm"] - ts["climatology"]) / ts["climatology_std"]
# Save anomaly metrics in pandas DataFrame
metrics = ["Absolute Anomalies", "Relative Anomalies", "Z-Scores"]
columns = ["abs_anomaly", "rel_anomaly", "z_score"]
ylabels = [f"Anomaly $[{SM_UNIT}]$", "Anomaly $[\%]$", "Z-score $[\sigma]$"]Now we create a plot for each anomaly metric derived from the extracted time series and climatology:
# Generate three time series plots for each anomaly metrics
fig, axs = plt.subplots(3, 1, figsize=(10, 7))
for i, (metric, col, ylabel) in enumerate(zip(metrics, columns, ylabels)):
axs[i].axhline(0, color="k")
axs[i].fill_between(ts[col].index, ts[col].values, where=ts[col].values >= 0, color="blue")
axs[i].fill_between(ts[col].index, ts[col].values, where=ts[col].values < 0, color="red")
axs[i].set_ylabel(ylabel)
axs[i].set_xlabel("Time [year]")
axs[i].set_title(f"Soil Moisture {metric} at Lon: {lon}° W, Lat: {lat}° N")
plt.tight_layout()
plt.show()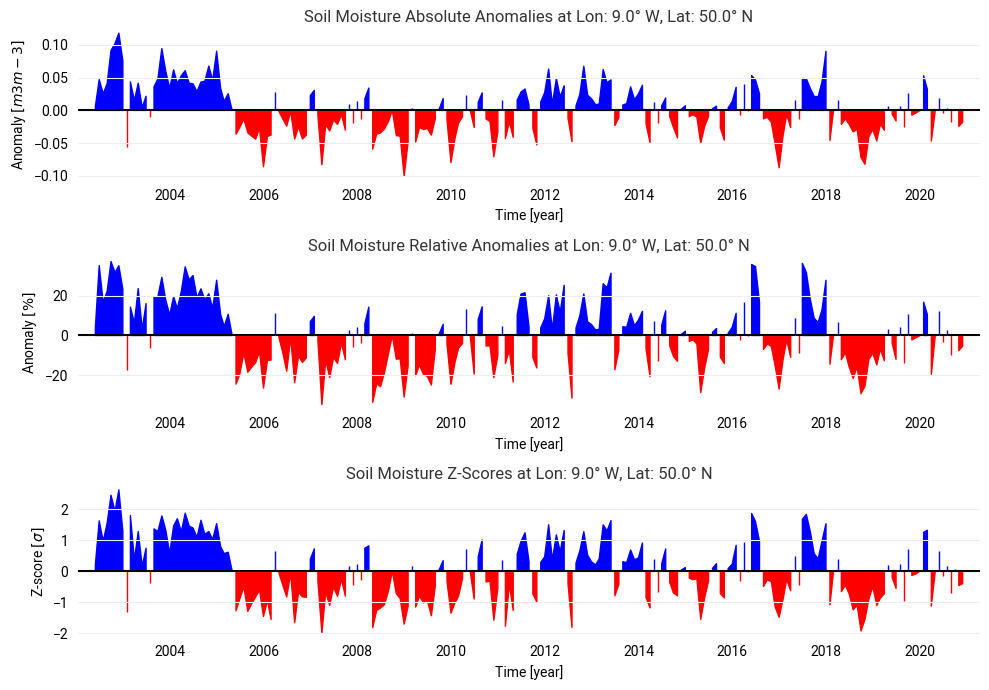
Choosing a different study area will change the input data and plot anomalies for a different ‘focus point’. You can also change the baseline period and see how it affects the climatology (and anomaly) computation. While the 3 time series look the same at first glance, there are some differences depending on the magnitude of the climatology and the intra-annual soil moisture variance in a point.
Use case 3: Vectorized Anomaly Computation¶
We will now compute the anomalies for the whole image stack (not only on a time series basis as in the previous example). For this we use some of the functions provided by xarray to group data. For the climatology (reference) we use all data from 1991 to 2020 (BASELINE_YEARS). This is the standard baseline period, but you can of course try a different period.
We will select all (absolute) soil moisture values in the reference period, group them by month (i.e. all January, February, ... values for all years in the baseline period) and compute the mean for each group. This way we get the CLIM stack, which consists of 12 images (one for each month):
BASELINE_YEARS = (1991, 2020)
STUDY_AREA = "Germany"
# select data in the climatology period and compute a monthly climatology stack
baseline_slice = slice(f"{BASELINE_YEARS[0]}-01-01", f"{BASELINE_YEARS[1]}-12-31")
CLIM = DS.sel(time=baseline_slice)["sm"].groupby(DS.sel(time=baseline_slice).time.dt.month).mean()
CLIMWe can now use the climatology stack and compute the difference between each image of absolute soil moisture and the climatological mean of the same month. This way we compute the anomalies for the whole data cube, without a time-consuming loop over all individual locations. We assign the result to a new variable in the DS stack called sm_anomaly:
DS["sm_anomaly"] = DS["sm"] - CLIM.sel(month=DS.time.dt.month).drop("month")We can use the bounding box of the chosen study area to extract all soil moisture values in the area of interest. We then compute the mean over all locations in the bounding box to get a single time series for the study area (MEAN_TS). Note that the coverage of C3S Soil Moisture varies over time (see the previous examples), which can also affect the value range of computed anomalies (standard deviation is usually larger for earlier periods).
subset = DS[["sm_anomaly"]].sel(
lon=slice(BBOXES[STUDY_AREA][0][0], BBOXES[STUDY_AREA][0][1]),
lat=slice(BBOXES[STUDY_AREA][0][3], BBOXES[STUDY_AREA][0][2]),
)
MEAN_TS = subset.mean(dim=["lat", "lon"]).to_pandas()We will resample the monthly soil moisture values in MEAN_TS with an annual frequency (“A”):
# Combine all data in the study area to an annual mean time series
mean_ts_annual = pd.Series(MEAN_TS["sm_anomaly"]).resample("A").mean()
mean_ts_annual.index = mean_ts_annual.index.year
# Create a plot to show the mean annual time series:
plt.figure(figsize=(10, 2))
mean_ts_annual.plot(
title=f"Annual mean soil Moisture anomaly for `{STUDY_AREA}`",
ylabel=f"SM anomaly $[{SM_UNIT}]$",
xlabel="Time [year]",
)
plt.show()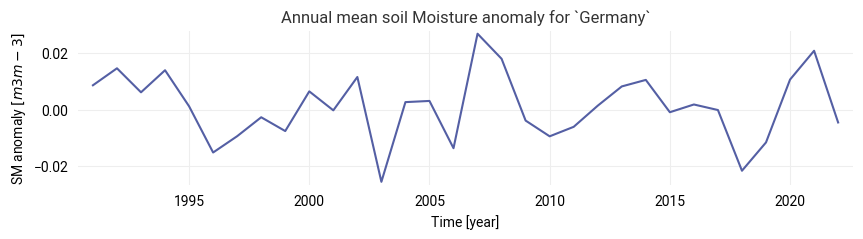
Now we can visualize the monthly anomalies from the processed anomaly stack as a bar plot. We will also create a map of annual mean values using the created time series for the whole study area bounding box. This is done for the year assigned to the variable YEAR in the next cell.
Try:
Plotting the annual anomalies for a different year (assign a different value to
YEARin the next cell).Changing
BASELINE_YEARSin this application and see how the chosen period affects values in the map and time series.
YEAR = 2018 # Choose a specific year to plot on the map
# Create a new figure with 2 subplots arranged in a 1:2 width ratio using GridSpec for flexible layout
fig = plt.figure(figsize=(15, 4), constrained_layout=True)
gs = fig.add_gridspec(1, 3)
map_ax = fig.add_subplot(
gs[0, 0], projection=ccrs.PlateCarree()
) # Create the first subplot for the map
ts_ax = fig.add_subplot(gs[0, 1:]) # Create the second subplot for the time series
### Creating the soil moisture anomaly map for the chosen year:
# Select all soil moisture anomaly data for the chosen year, compute the average, and plot it on the map
DS["sm_anomaly"].sel(time=slice(f"{YEAR}-01-01", f"{YEAR}-12-31")).mean("time").plot(
transform=ccrs.PlateCarree(),
ax=map_ax,
cmap=plt.get_cmap("RdBu"),
cbar_kwargs={"label": f"Anomaly [{SM_UNIT}]"},
)
# Add geographical features to the map for better context
map_ax.axes.add_feature(cartopy.feature.LAND, zorder=0, facecolor="gray") # Add land features
map_ax.axes.coastlines() # Add coastlines
map_ax.add_feature(cartopy.feature.BORDERS) # Add country borders
map_ax.set_title(f"{YEAR} - Soil Moisture Anomaly") # Set the title of the map subplot
# Plot the bounding box of the study area on the map
bbox = BBOXES[STUDY_AREA][0]
map_ax.plot(
[bbox[0], bbox[0], bbox[1], bbox[1], bbox[0]],
[bbox[2], bbox[3], bbox[3], bbox[2], bbox[2]],
color="red",
linewidth=3,
transform=ccrs.PlateCarree(),
)
# Add grid lines to the map
gl = map_ax.gridlines(crs=ccrs.PlateCarree(), draw_labels=True, alpha=0.25)
gl.right_labels, gl.top_labels = False, False
### Creating the soil moisture anomaly time series plot:
# Plot the annual time series of soil moisture anomaly for the study area as a bar plot
bars = ts_ax.bar(mean_ts_annual.index, mean_ts_annual.values)
ts_ax.set_title(f"Annual conditions in `{STUDY_AREA}` study area")
ts_ax.set_xlabel("Year")
ts_ax.set_ylabel(f"Anomaly [{SM_UNIT}]")
ts_ax.axhline(y=0, color="black", linewidth=1)
# Highlight the bar corresponding to the selected year and color bars based on the sign of the anomaly
for i, bar in enumerate(bars.patches):
if mean_ts_annual.values[i] > 0:
bar.set_facecolor("blue") # Color positive anomalies blue
else:
bar.set_facecolor("red") # Color negative anomalies red
if mean_ts_annual.index.values[i] == YEAR:
bar.set_edgecolor("k") # Highlight the selected year's bar with a black edge
bar.set_linewidth(3)
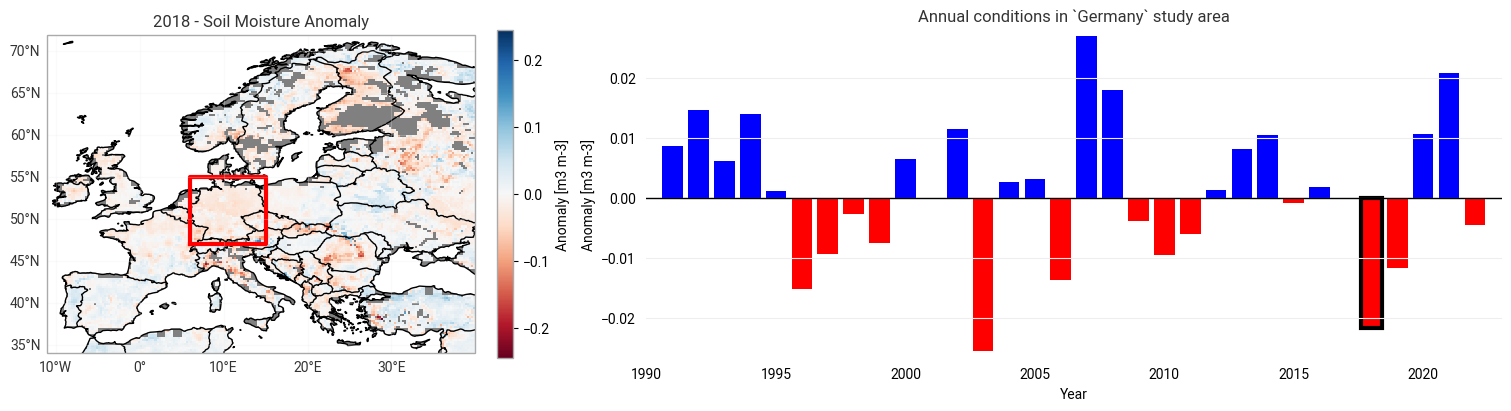
We see an overall trend towards drier conditions in most regions. You can look at a different study area by selecting it in the first application. Don’t forget to re-run all relevant cells in this chapter to use the new study area and accordingly update the plots!
References¶
Dorigo, W., Wagner, W., Albergel, C., Albrecht, F., Balsamo, G., Brocca, L., Chung, D., Ertl, M., Forkel, M., Gruber, A., Haas, E., Hamer, P.D., Hirschi, M., Ikonen, J., De Jeu, R., Kidd, R., Lahoz, W., Liu, Y.Y., Miralles, D., Mistelbauer, T. Nicolai-Shaw, N., Parinussa, R., Pratola, C., Reimer, C., van der Schalie, R., Seneviratne, S.I., Smolander, T., Lecomte, P. (2017) ESA CCI Soil Moisture for improved Earth system understanding: State-of-the-art and future directions. Remote Sensing of the Environment, 203, 185-215. Doi: 10.1016/j.rse.2017.07.001.
Gruber, A., Scanlon, T., van der Schalie, R., Wagner, W., Dorigo, W. (2019) Evolution of the ESA CCI Soil Moisture climate data records and their underlying merging methodology. Earth System Science Data, 11(2) 717-739. Doi: 10.5194/essd-11-717-2019.
Rodell, M., Houser, P.R., Jambor, U., Gottschalck, J., Mitchell, K., Meng, C.-J., Arsenault, K., Cosgrove, B., Radakovich, J., Bosilovich, M., Entin, J.K., Walker, J.P., Lohmann, D., Toll, D. (2004) The Global Land Data Assimilation System. Bulletin of the American Meteorological Society, 85(3), 381-394. Doi: 10.1175/BAMS-85-3-381.
- Owe, M., & Van de Griend, A. A. (1998). Comparison of soil moisture penetration depths for several bare soils at two microwave frequencies and implications for remote sensing. Water Resources Research, 34(9), 2319–2327. 10.1029/98wr01469
- Owe, M., de Jeu, R., & Walker, J. (2001). A methodology for surface soil moisture and vegetation optical depth retrieval using the microwave polarization difference index. IEEE Transactions on Geoscience and Remote Sensing, 39(8), 1643–1654. 10.1109/36.942542
- Schalie, R. van der, Kerr, Y. H., Wigneron, J. P., Rodríguez-Fernández, N. J., Al-Yaari, A., & Jeu, R. A. M. de. (2016). Global SMOS Soil Moisture Retrievals from The Land Parameter Retrieval Model. International Journal of Applied Earth Observation and Geoinformation, 45, 125–134. 10.1016/j.jag.2015.08.005
- Wagner, W., Lemoine, G., & Rott, H. (1999). A Method for Estimating Soil Moisture from ERS Scatterometer and Soil Data. Remote Sensing of Environment, 70(2), 191–207. 10.1016/s0034-4257(99)00036-x
- Dorigo, W., Wagner, W., Albergel, C., Albrecht, F., Balsamo, G., Brocca, L., Chung, D., Ertl, M., Forkel, M., Gruber, A., Haas, E., Hamer, P. D., Hirschi, M., Ikonen, J., de Jeu, R., Kidd, R., Lahoz, W., Liu, Y. Y., Miralles, D., … Lecomte, P. (2017). ESA CCI Soil Moisture for improved Earth system understanding: State-of-the art and future directions. Remote Sensing of Environment, 203, 185–215. 10.1016/j.rse.2017.07.001
- Gruber, A., Scanlon, T., van der Schalie, R., Wagner, W., & Dorigo, W. (2019). Evolution of the ESA CCI Soil Moisture climate data records and their underlying merging methodology. Earth System Science Data, 11(2), 717–739. 10.5194/essd-11-717-2019
- Rodell, M., Houser, P. R., Jambor, U., Gottschalck, J., Mitchell, K., Meng, C.-J., Arsenault, K., Cosgrove, B., Radakovich, J., Bosilovich, M., Entin, J. K., Walker, J. P., Lohmann, D., & Toll, D. (2004). The Global Land Data Assimilation System. Bulletin of the American Meteorological Society, 85(3), 381–394. 10.1175/bams-85-3-381